The parent guide AI API caching covers the broader caching strategy; this article goes one level into Anthropic's specific implementation.
What it caches and why
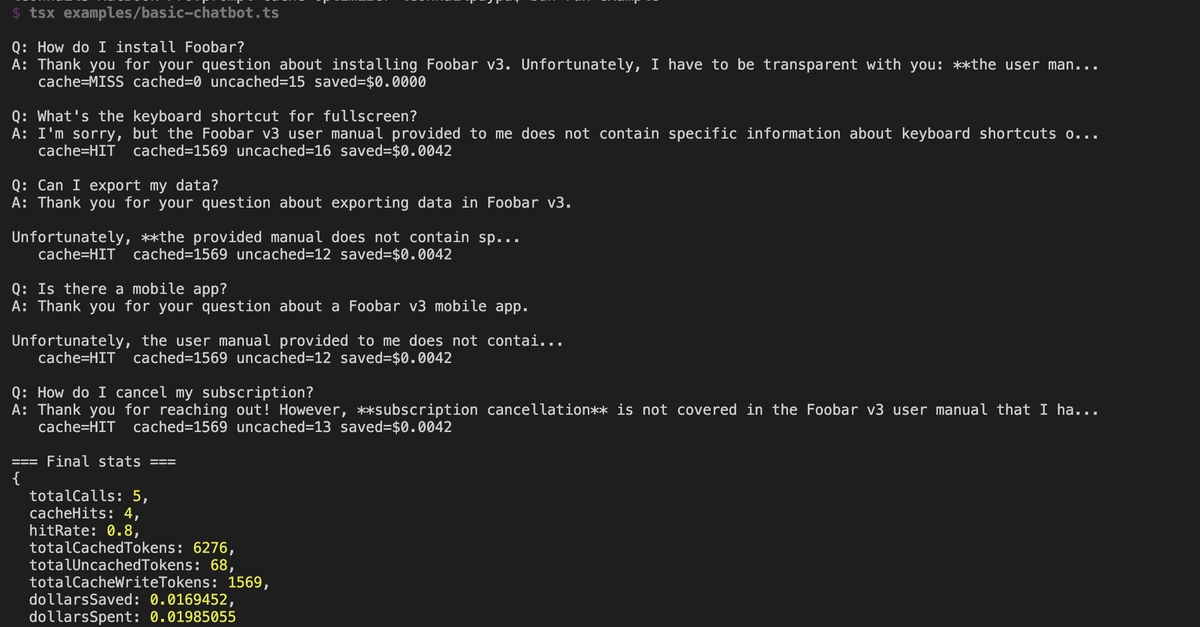
Prompt caching is provider-side prefix-attention caching. When you send a request to Anthropic with cache_control: { type: "ephemeral" } on part of the prompt, Anthropic hashes the leading content up to that marker, checks an internal cache, and serves the cached attention state if a match exists. The actual model run still happens — Claude still generates the response token-by-token — but the expensive prefix-attention computation is skipped.
The "cache" here is not the response. It's the work the model does to encode the static context into the model's internal representation. Most production LLM workloads carry a long stable prefix (system prompt + retrieved context + tool definitions) followed by a short variable suffix (the user message). Re-encoding the stable prefix on every request is wasted compute. Anthropic charges less for the cached portion because it's doing less work.
The pricing math