Vector RAG is the reflexive answer to "give the model more context," and when I built a production tutoring AI, I reached for it too. The product is simple: a student uploads a photo of a problem, and our tutor explains it step by step and produces an answer. Our client also had a large database of past problems, stored as images — and of course we wanted to leverage it. So the system retrieved the most similar past problem and fed it, together with its answer, into the model to help generate a solution. It was such an obvious move that I never questioned it.
It performed poorly.
I went hunting for the usual suspect: retrieval quality. I tried different retrieval strategies, from matching on the problem description to matching on the image content. I benchmarked different embedding models, from single-vector to late-interaction. None of it moved the needle. If retrieval quality wasn't the problem, where was the bug?
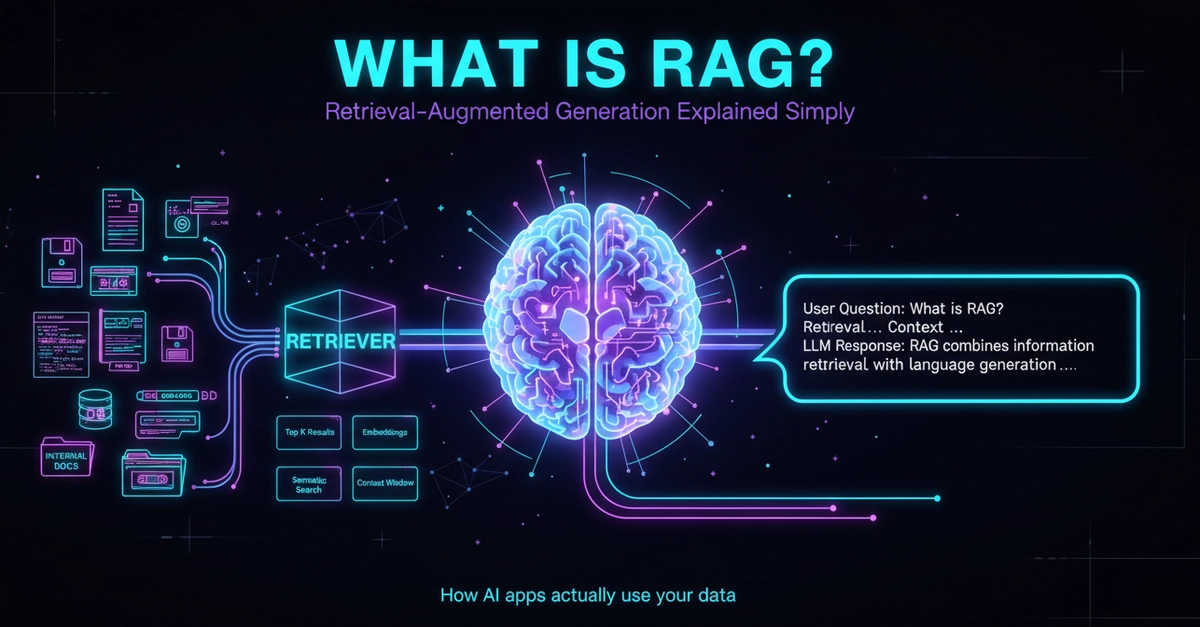
Vector RAG represents text or images in an embedding space and returns the stored chunk whose meaning is closest to the query. In other words, it optimizes for exactly one thing: semantic similarity to what you've already stored. Hidden inside that is a silent assumption — that the most similar stored item is the one the model needs. For FAQs or document lookup, the assumption holds: the most similar passage really is the right one, so RAG is never wrong there, and reaching for it feels so natural that the assumption never surfaces. The tool isn't the problem; it does exactly what it claims. The real question is whether most similar == what's needed holds for your case — and you have to check that before reaching for it.