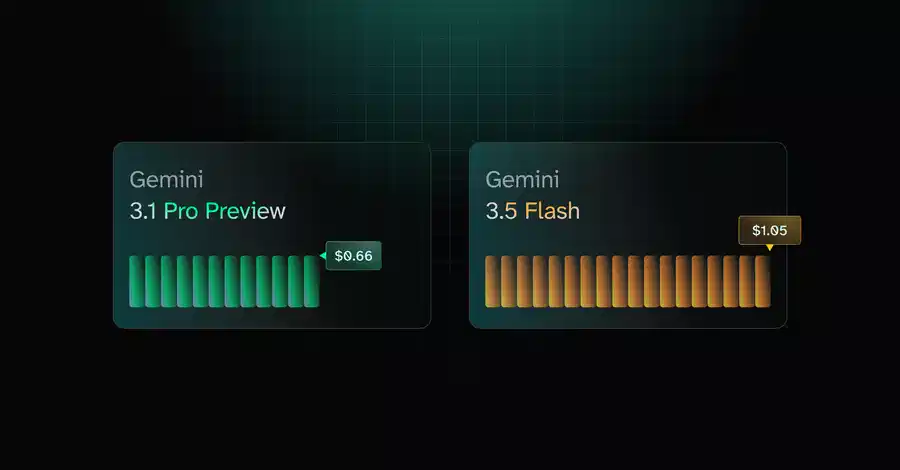
I'd routed the same one-word prompt to Claude Haiku and to Gemini 2.5 Flash. Flash has the lower per-token price, so this should have been an easy win. It wasn't. Flash is a thinking model: before it answered "Paris," it spent a few dozen tokens reasoning, and reasoning is billed as output. Haiku answered in 4 tokens. Flash spent about 28 — lower unit price, far more units, ~8.6× the bill per request. I only caught it because I'd instrumented every call: tokens, cost, latency, written to Postgres. And I instrument every call because that's what you do when you've spent years keeping payment systems honest.
That instinct is the whole point. For two and a half years I built cross-border real-time payments at NPCI — the kind of system where a rounding error is an incident and a downstream going dark is a Saturday night. This year I built an LLM gateway, and I kept reaching for the same tools. That's not a coincidence.
AI infrastructure looks like a new field. Underneath, it's the systems work backend engineers have always done. A model API is a downstream dependency: it's slow, it's occasionally down, it rate-limits you, and it bills you per call. You have integrated a dependency exactly like that before — a payment processor, a KYC provider, a partner bank. The model isn't magic. It's a new kind of expensive, flaky downstream, and the hard parts — reliability, cost control, failover — are the parts we already solved.