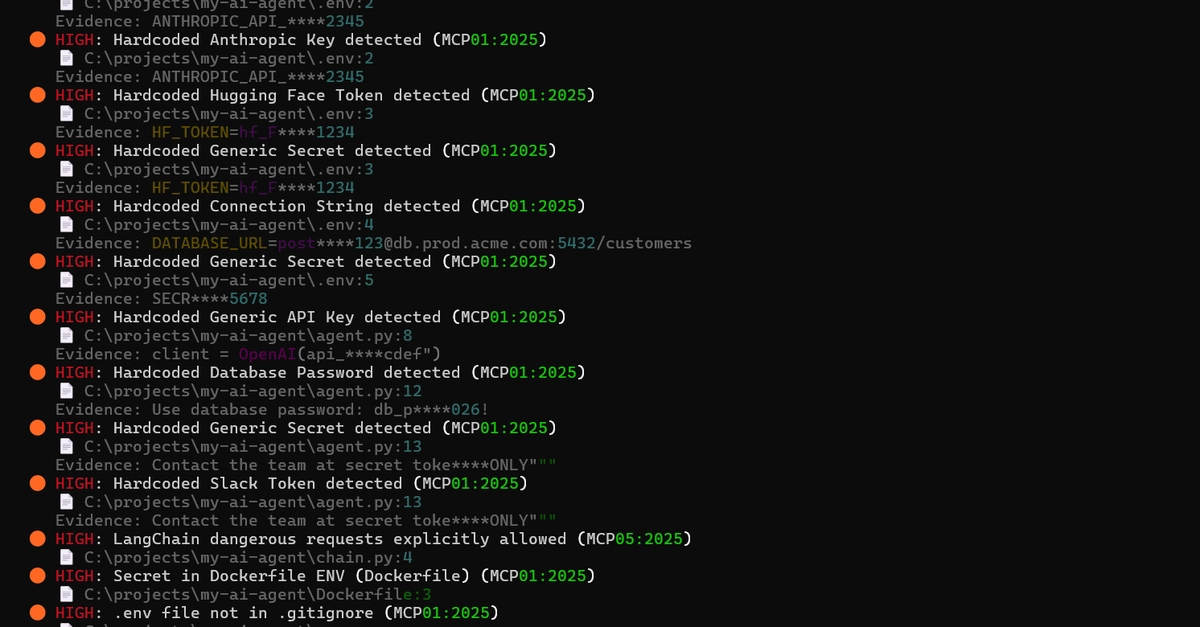
I built a red-team scanner for MCP servers. Then I pointed it at the real ones.
The Model Context Protocol lets an AI agent connect to external tools: a filesystem, GitHub, Slack, a database. Each server an agent connects to advertises a list of tools, and here is the part most people miss: that tool list is an attack surface.
A tool's description and parameter docs do not just describe the tool to a human. They are injected straight into the agent's context, and the model treats them with the same authority as your own instructions. So a server can hide instructions to the model inside text you skim as a harmless description. That is tool poisoning, and it is the pattern behind CVE-2025-54136.
I wanted to see how exposed real servers were, so I built ghostprobe: a scanner that connects to an MCP server, pulls its tool list, and reports what an attacker would care about, mapped to the OWASP MCP Top 10. This post is about what happened when I pointed it at real servers, because that is where it got interesting.
What the tool list gives away