Originally published at kalyna.pro
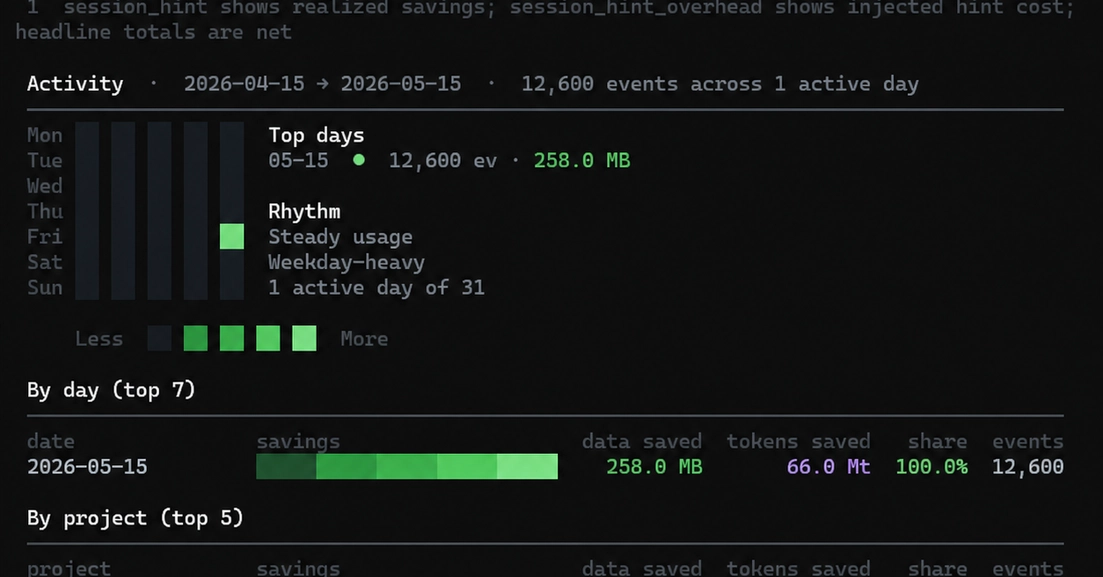
If your app sends the same large system prompt, tool definitions, or document context on every request, you're paying full price to re-process those tokens every single time. Prompt caching lets Claude reuse the processed representation of a prompt prefix across requests — cache hits cost 90% less than normal input tokens. This guide covers how caching actually works, the pricing math for writes vs reads, where to place cache breakpoints, and worked cost examples for RAG apps and agents.
Prerequisites
pip install anthropic
Enter fullscreen mode