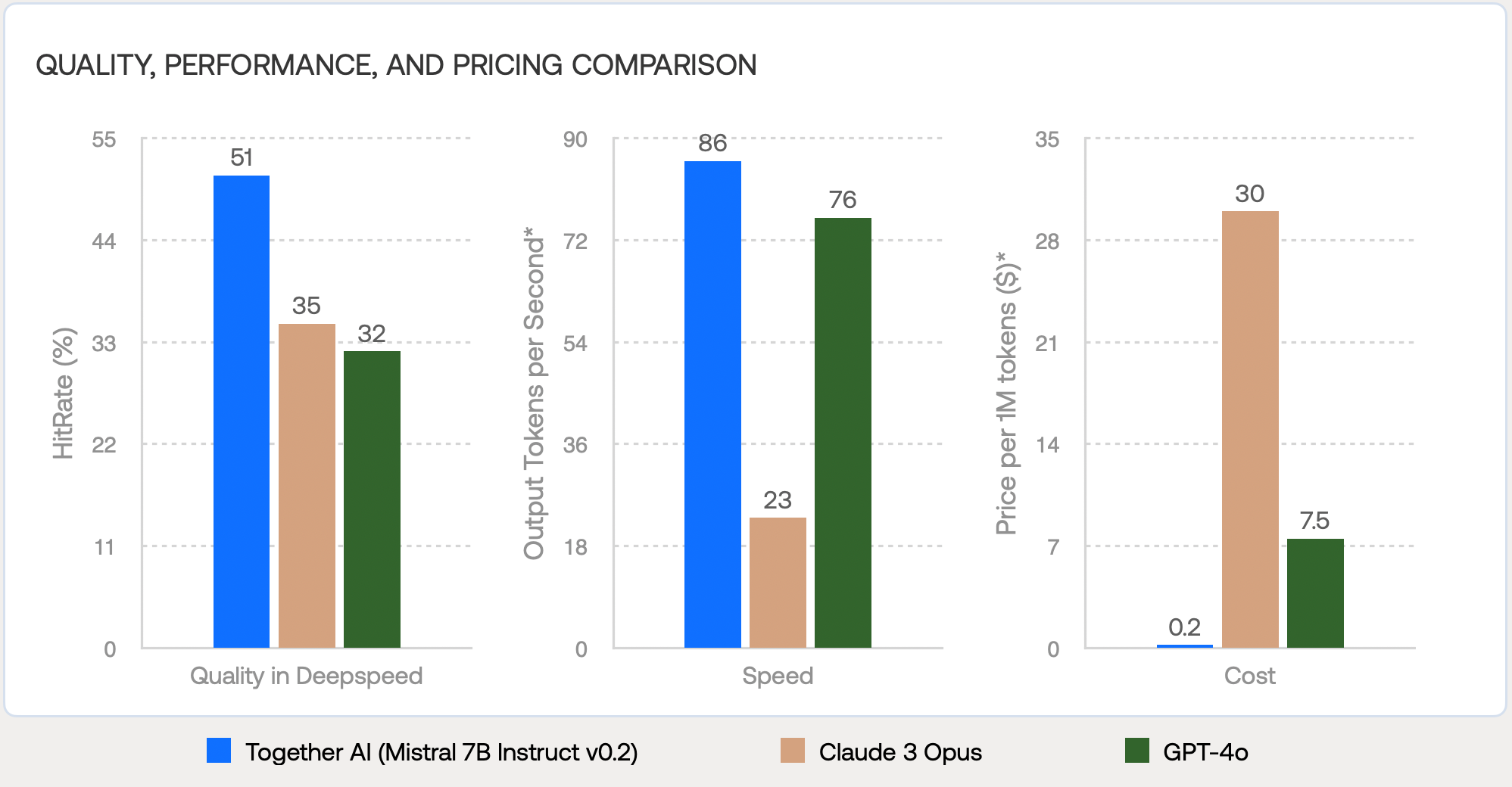
I built GroundCheck, a small open model that checks whether an AI answer is actually supported by the source it cites. It scores 0.682 F1 on the RAGTruth benchmark, ahead of the published GPT-4-turbo-as-judge baseline (0.634), and it returns a verdict in under a second on a laptop CPU. Total compute cost: zero — every training run fit inside Kaggle's free GPU quota.
Weights, benchmark code, and a pip package are public. This post is the honest version of how it went, including the part where the first model failed.
The problem
RAG pipelines answer questions from documents, and sometimes they state things the documents never said: a number quietly changed, "increased" turned into "decreased," a plausible fact invented from nowhere. Checking every answer with a frontier LLM-as-judge works, but it is slow (seconds), priced per token, and ships your data to a third party.
This is a narrow classification task, and narrow tasks are where small specialized models earn their keep. Premise: source document (plus the user's question when available).