I just shipped a 12-part video series on cloud economics - depreciation schedules, lock-in, licensing disputes, bundling cases. The kind of material where one sloppy sentence gets you a lawyer's letter, and one unsourced number gets you dismissed as a crank.
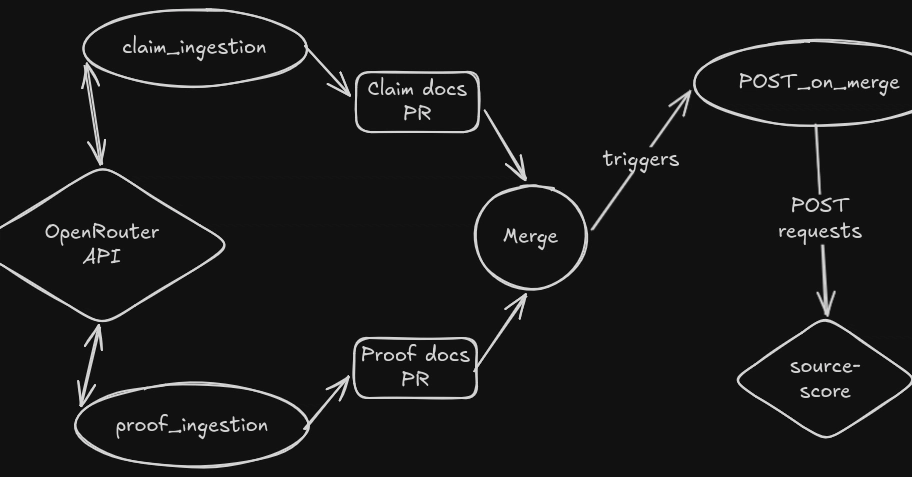
So before writing a single script, we built a sourcing pipeline. This post is about that pipeline - treating an investigation like an engineering project, with schemas, gates, and review passes - because I think the discipline transfers to anyone writing technical content that makes claims about real companies.
The core artifact: claims.json
Every episode started not as a script but as a structured claims file. Each claim is a record with a few mandatory fields:
{