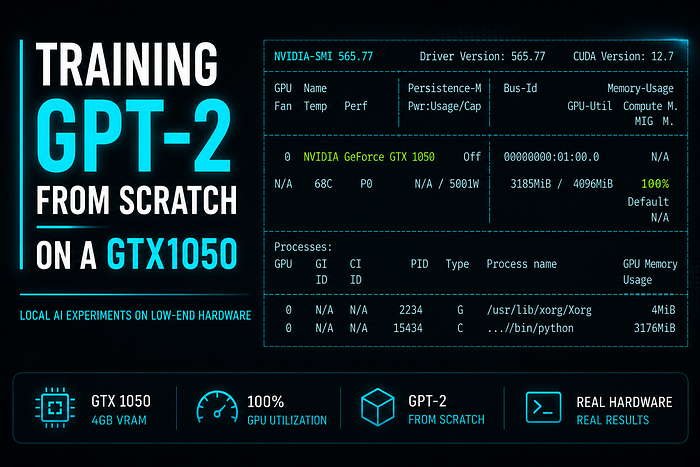
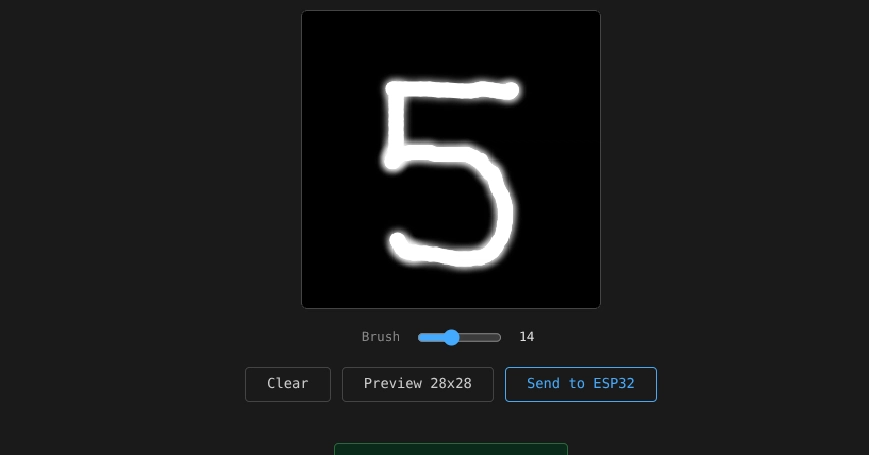
Training a network from scratch in raw NumPy, quantizing it to int8, and running it as ~80 lines of dependency-free JavaScript — with a parity test proving the browser matches Python to 1e-6.
Why bother? MNIST is a solved problem
Digit recognition is the "hello world" of ML — that's exactly why I used it. The model isn't the point. The point is everything around the model, which happens to be the part that matters in production work too: training without a framework, compressing for deployment, running inference in a constrained environment, and proving the deployed system matches the trained one.
Training: just NumPy and math
The network is a 784→128→64→10 MLP — hand-written forward pass, backpropagation, and Adam optimizer. No autograd, no framework: