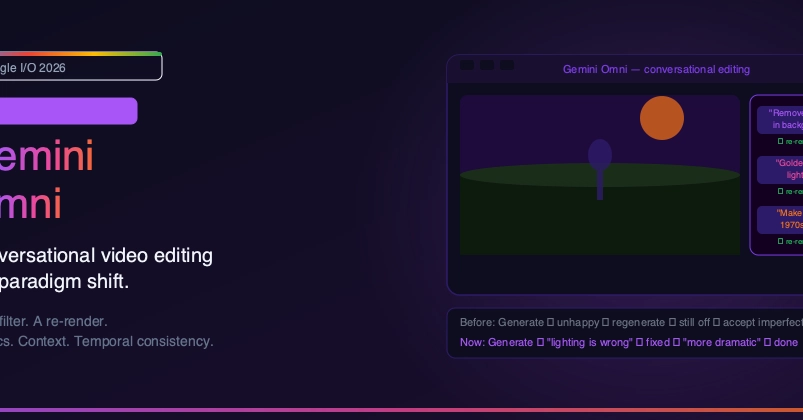
If you’ve played around with current AI video generators, you already know the frustration: It’s basically a slot machine.
You write a massive prompt, hit "generate," wait 3 minutes, and pray. If the lighting is wrong, or the character's jacket changed color? You have to rewrite the prompt and re-roll the dice. You lose all your previous progress.
As a developer, this lack of "state" drove me crazy. Why can't we have version control or iterative diffs for video generation? Why can't I just tell the AI, "Keep everything exactly the same, but make it rain in the background"?
I decided to fix this by ditching the traditional NLE (Non-Linear Editor) timeline entirely and building a conversational video generator powered by Google's Gemini Omni model.
Here is how I built it, the technical hurdles of maintaining "video state," and why I think conversational UI is the future of video editing.