TL;DR
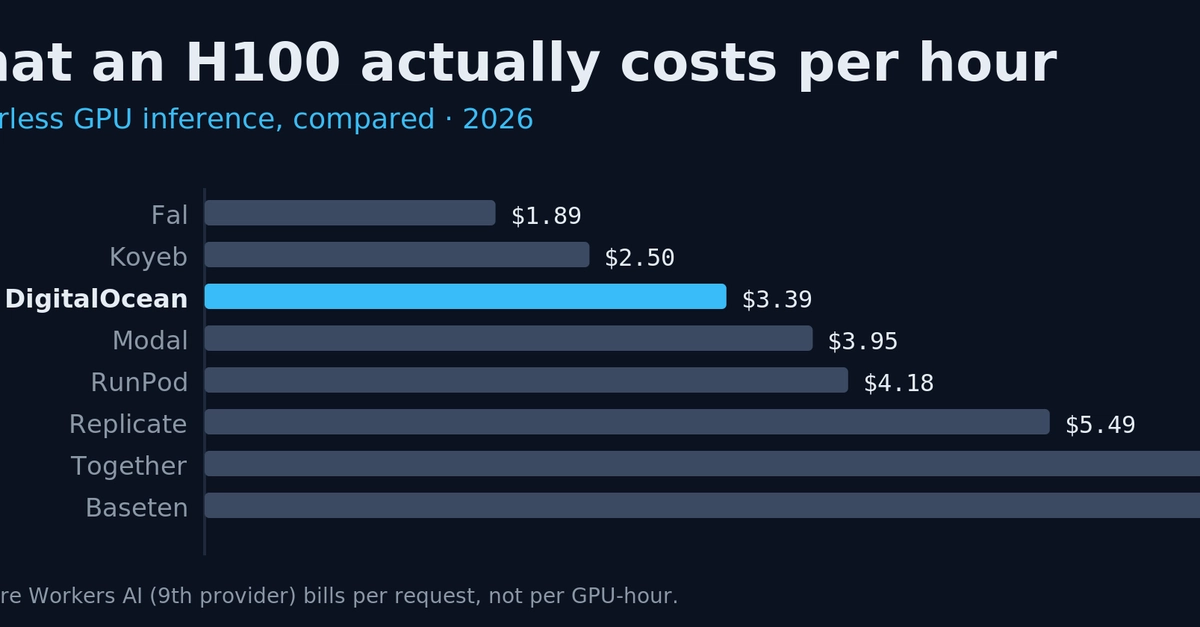
If you're shipping AI inference and tired of babysitting GPUs, serverless is the way out. You deploy the model, the platform scales it from zero to hundreds of GPUs and back, and you only pay for the time you actually use. If I'm picking one to start with, it's DigitalOcean. It's got the widest GPU lineup of any serverless provider (RTX 4000 Ada all the way up to NVIDIA Blackwell B300 and AMD's MI350X), one API and one bill instead of five, and it's simple enough to ship on without a sales call. (More on why that one's personal for me below.)
Below I compare 9 providers across the things that actually matter: GPU specs, per-hour pricing, cold-start latency, model support, and how nice they are to build on. DigitalOcean, RunPod, Modal, Koyeb, Together AI, Replicate, Baseten, Fal, and Cloudflare Workers AI each win at something different, from cheap experimentation to global edge inference.
Contents
Why I ran this