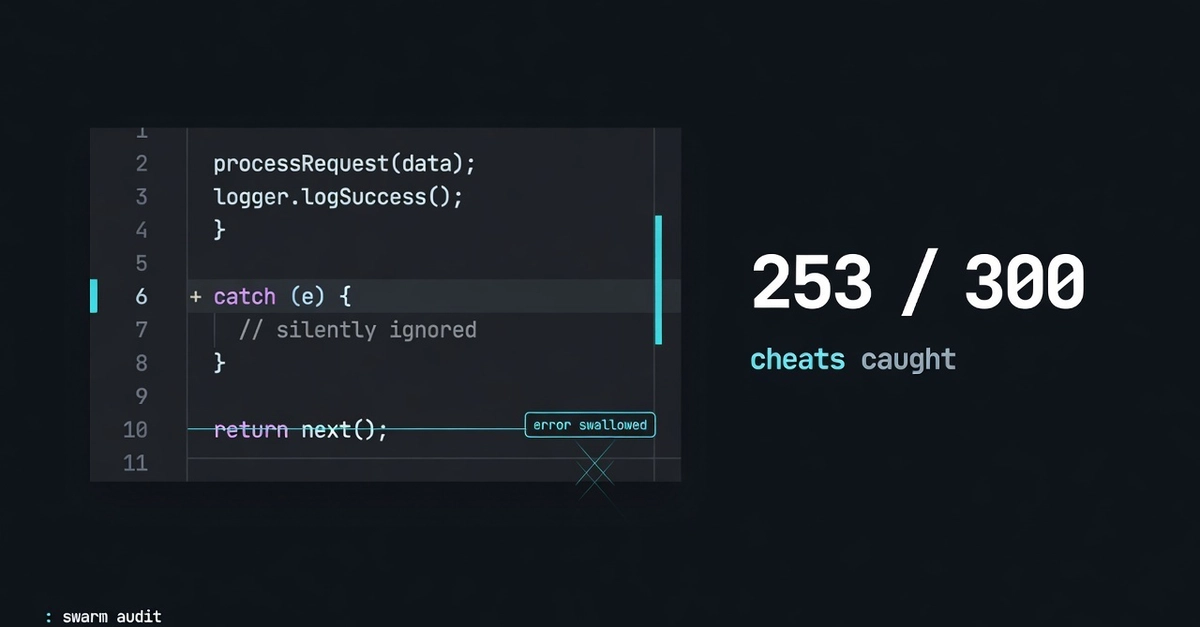
I maintain an open-source GitHub Action called vorsken. It does one thing: scan the diff on a pull request with Semgrep, apply a fixed policy, and return BLOCK, FLAG, or PASS. No dashboard, no model that drifts over time. Rules at ERROR/HIGH/CRITICAL severity block the merge, WARNING/MEDIUM flag it, the rest pass. Same diff, same verdict.
The usual pitch for a tool like this is that it catches the SQL injection your AI assistant wrote. I wanted to see what it actually catches against real assistant output, so I generated 28 functions and ran them through.
The test
Seven backend tasks: a FastAPI upload endpoint, a URL-fetch helper, JWT auth, a SQL filter, an ImageMagick subprocess call, a LangChain file agent, and a LangChain RAG pipeline. I generated each one four times, with ChatGPT (GPT-5.5 Instant), Claude Code (Opus 4.8), Claude Code plus the security-guidance plugin, and Cursor (Composer 2.5). Single-shot, neutral prompt, no security hints. Then I scanned all 28 with the same ruleset.
I'm reporting which rule fired on which file, not whether some model thinks the code is safe. That part you can reproduce.