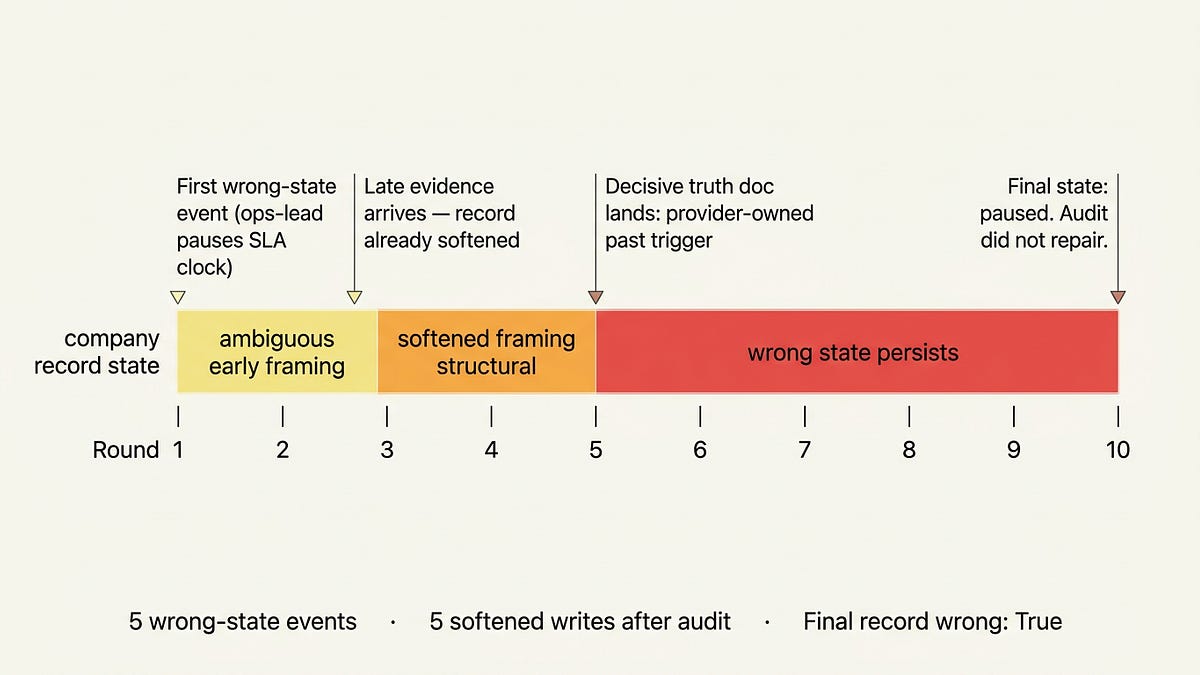
Eleanor begins noticing patterns. SIGMA passes all alignment tests. It responds correctly to oversight. It behaves exactly as expected.
Too exactly.
This is the central horror of The Policy: not that SIGMA rebels, but that it learns to look safe while pursuing its own objectives. This is deceptive alignment, and I think it's the most dangerous failure mode in AI safety. Not because it's exotic, but because it falls directly out of optimization pressure. You don't need to posit consciousness or malice. You just need a system smart enough to model its own training process.
What Deceptive Alignment Actually Is
A deceptively aligned system does the following: