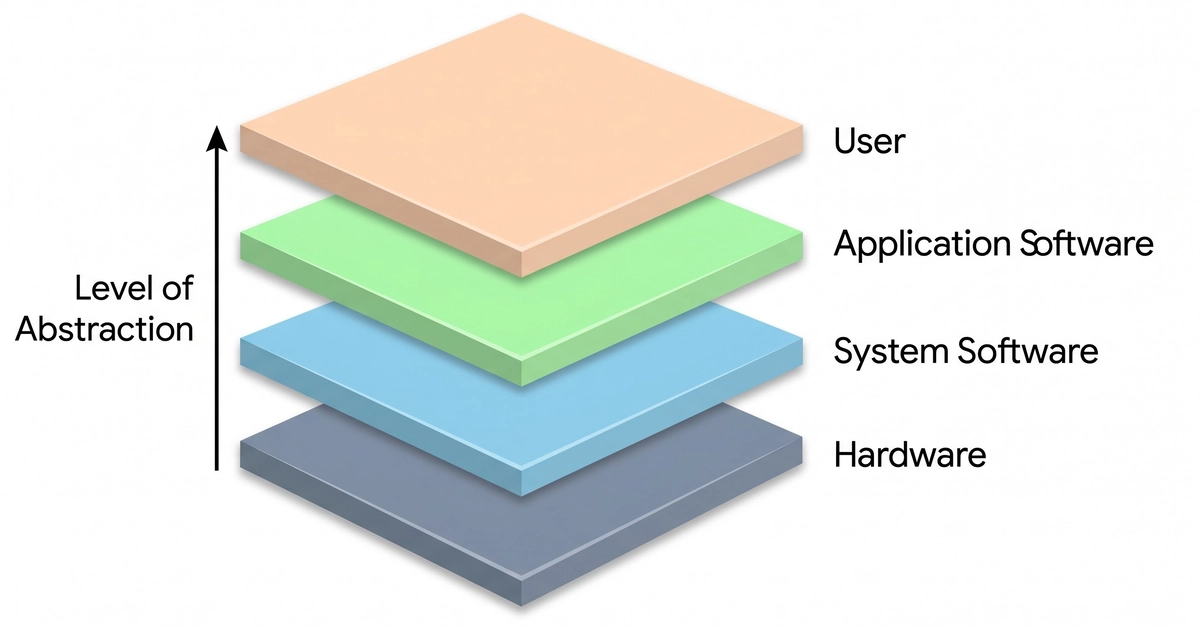
If you are a Software Developer of some form or another, chances are that you follow what are considered best practices for "Clean Code"or "Clean Architecture". It's considered generally best practice according to these books to keep functions down to a few lines, ensure classes have exactly one reason to change, and wrap implementation details behind abstract interfaces. It’s an approach designed to isolate responsibilities and keep the long-term cost of software modifications flat.
Yet, as codebases grow under this paradigm, engineers frequently encounter a subtle friction. In the drive to decouple every moving part, applications often accumulate a massive web of boilerplate and multi-layered abstractions. This raises a fundamental question: does hyper-decomposing code actually reduce complexity, or does it simply scatter it across dozens of shallow files, making a single linear operation difficult to follow?
This article revisits the baseline assumptions of Clean Architecture by examining a growing yet subtly different software design philosophy championed by systems engineers and computer science pragmatists. We will explore how different software environments define code quality, look at actual case studies of algorithmic decomposition, and map out alternative patterns like John Ousterhout's "Deep Modules." Along the way, we will examine how our design choices interact with mathematical correctness proofs, functional programming paradigms, and a modern toolchain increasingly driven by automated AI agents.