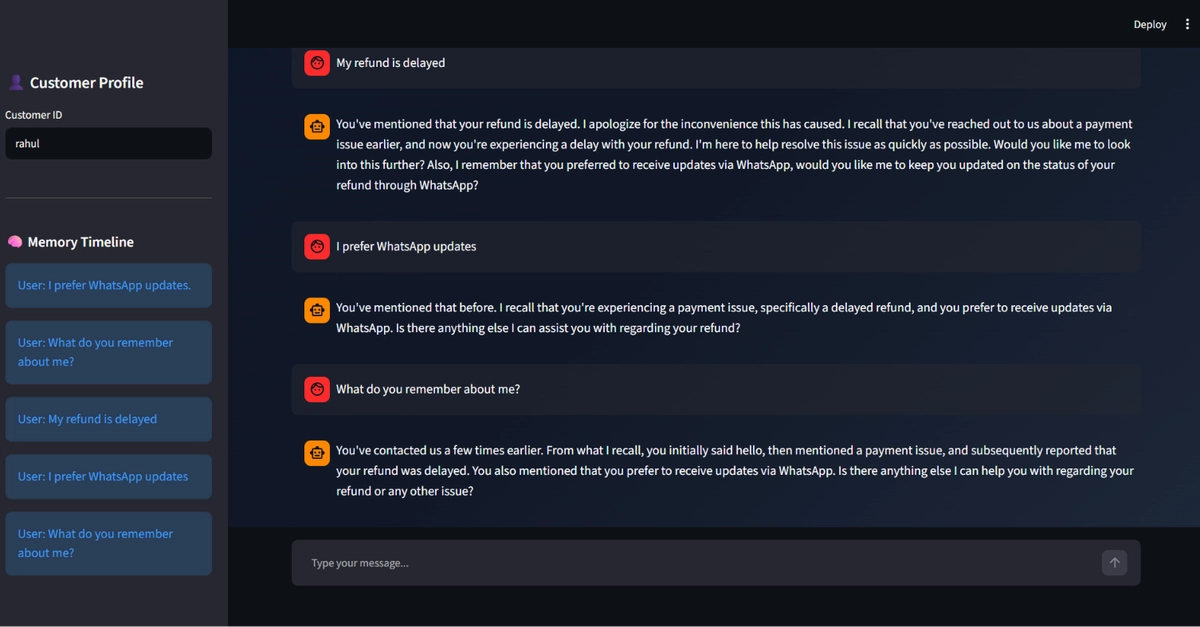
If you have ever built a production-grade LLM agent for customer support, you know the exact moment your token bills spike and your agent's responses fall off a cliff. It is the moment you decide to pass the entire raw chat history into the system prompt in a naive attempt to give the agent a "long-term memory."
When we first built our customer support agent—designed as a full PERN stack application (PostgreSQL, Express, React, and Node.js) running on Llama 3.3 via Groq—we went down this exact path. We appended every past user message and agent response to a rolling context window. In demo settings with small, single-turn interactions, it worked beautifully. In the real world, the wheels quickly fell off. The agent suffered from context window fatigue, mixed up past troubleshooting sessions, and suffered from massive latency spikes as system prompt lengths expanded.
Here is how we moved away from raw chat history injection to a structured, dual-bank cognitive memory architecture using Hindsight, and why we chose not to rely on vector databases or generic RAG hacks.
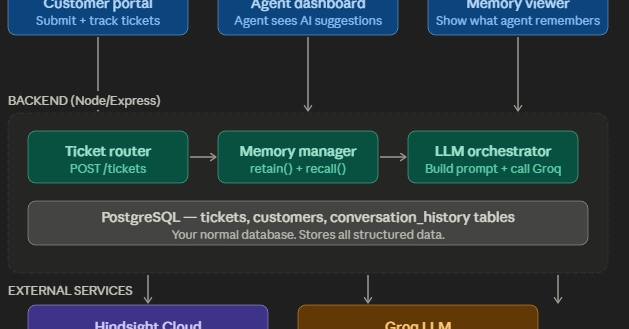
The System Architecture: How It Hangs Together
Our customer support system is built on a PERN stack architecture, coordinating three distinct layers: