This is part 3 of the Adaptive Model Routing series. Part 1 built an LLM categorizer with Groq — 8 categories, 3 tiers. Part 2 added k-NN embedding lookup in shadow mode, discovered 83% tier accuracy, and found 61% cost savings on paper. This post covers what happened next.
When Phase 2 ended, I had a working embedding pool in shadow mode inside crab-bot. The category accuracy was sitting at 78.6%. Not bad — but the breakdown hid something worth looking at.
Phase 3: When Validation Tells You a Category Doesn't Need to Exist
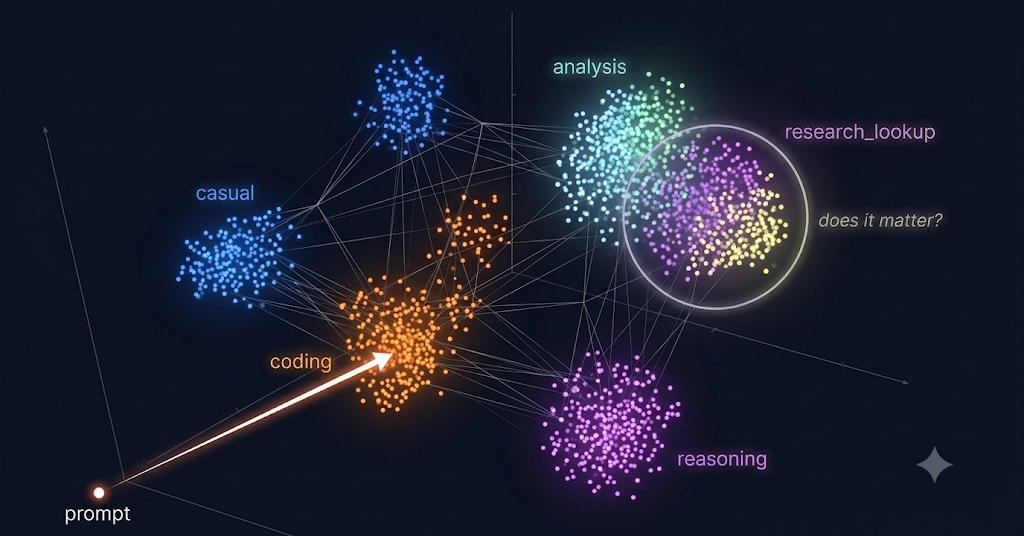
The leave-one-out accuracy by category told the real story:
Category