Originally published at htpbe.tech. The version on htpbe.tech stays in sync with the latest detection algorithm — refer to it for the canonical text.
PDF fraud is a backend problem. It happens before your business logic runs — at the moment your application accepts a document it has no reason to distrust. By the time a reviewer opens a bank statement, invoice, or diploma, the data from that document may have already influenced an automated decision.
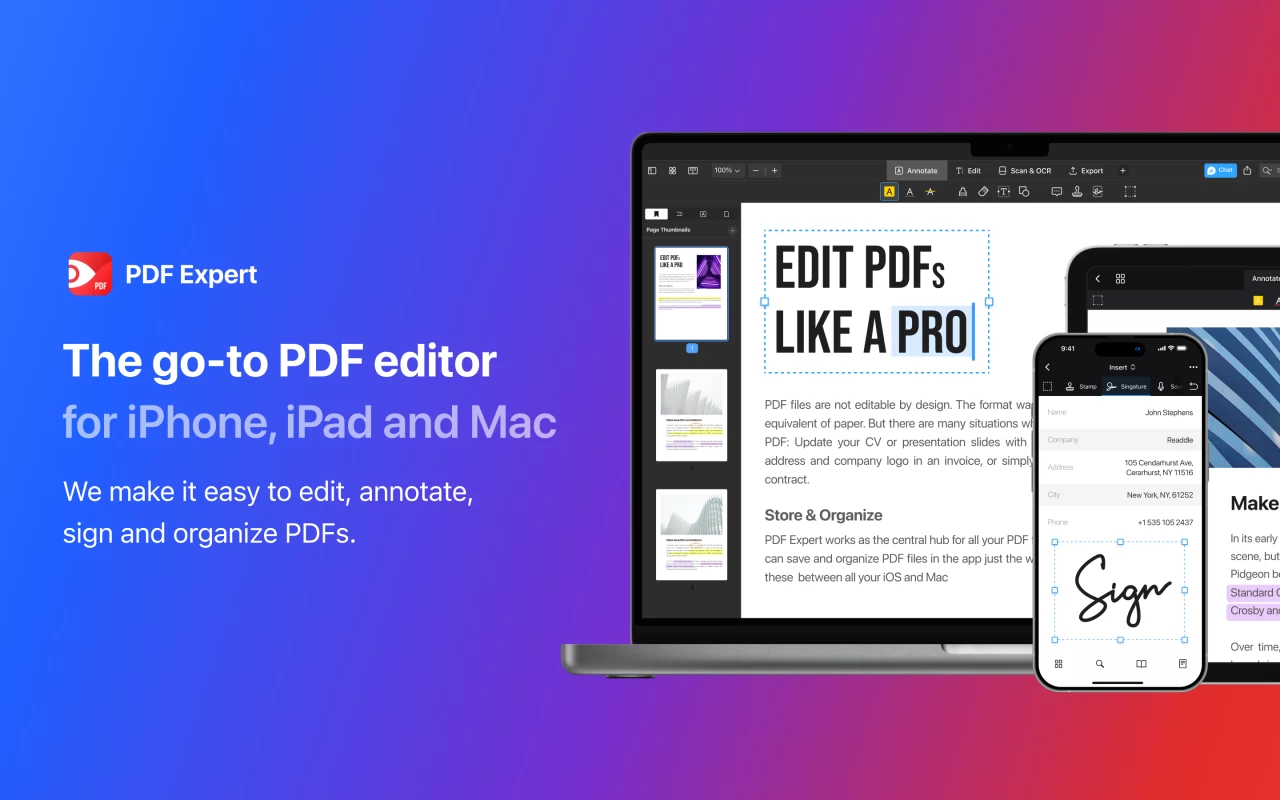
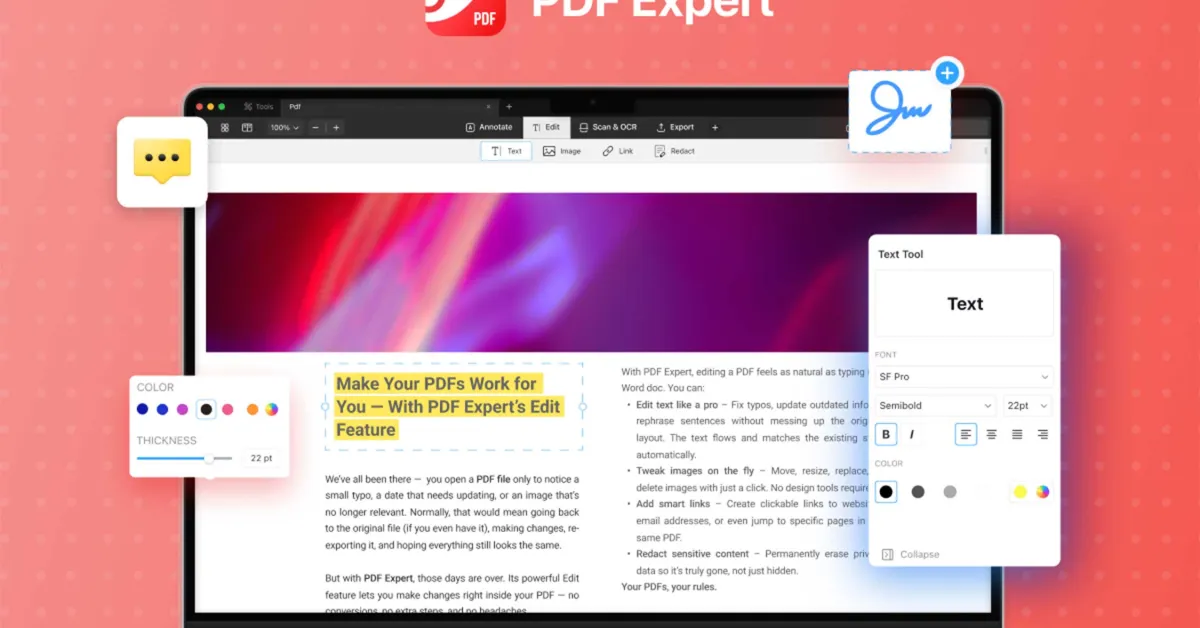
This guide is about catching that before it reaches your business layer. We will look at what signals inside a PDF reveal tampering, and how to integrate forensic PDF tamper detection into a backend application using the HTPBE API. For language-specific walkthroughs with complete production-ready code, see the Node.js integration guide or the Python integration guide.
What makes PDF tampering detectable
PDF is not a flat format. When a PDF is created or edited, it leaves a structural record of what happened and when. Most editors do not erase these records — they append to the file. A forensic analysis does not need the original document to detect changes; it reads what the file itself preserved.