For the past ten days I've been building a GitHub bot that reviews pull requests against a team's own written conventions. Not a generic "linter with vibes" reviewer — a small, focused one that knows the specific rules your team has agreed to: the kind that live in CLAUDE.md files, onboarding docs, and Notion pages nobody reads anymore.
I want to write about it because, honestly, I'm a little obsessed. Not with the bot itself (which is fine, it's a sprint project), but with the shape of the problem — what it actually takes to make an LLM useful, repeatable, and measurable at a real task. There's a version of "AI tooling" right now that's all vibes and demos. There's a different version where you have to build the boring substrate first. This sprint was a tour of the boring substrate, and I came out of it more curious than when I started, not less.
Source is public at github.com/azaz101hassan/ai-pr-review-copilot.
What I built
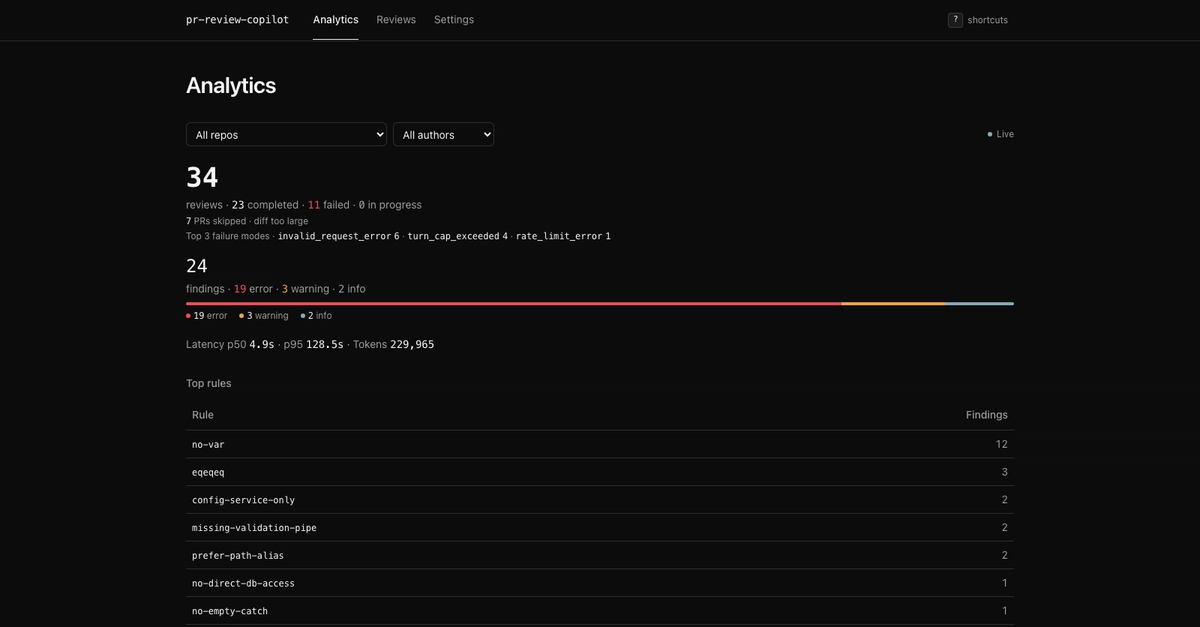
The bot listens for GitHub pull_request webhooks, runs a multi-turn agent loop over the diff against a vector-indexed knowledge base of team conventions, and posts findings as inline review comments plus a single walkthrough comment. A Next.js dashboard reads from the same SQLite store so an operator can see at a glance what the bot has been doing.





