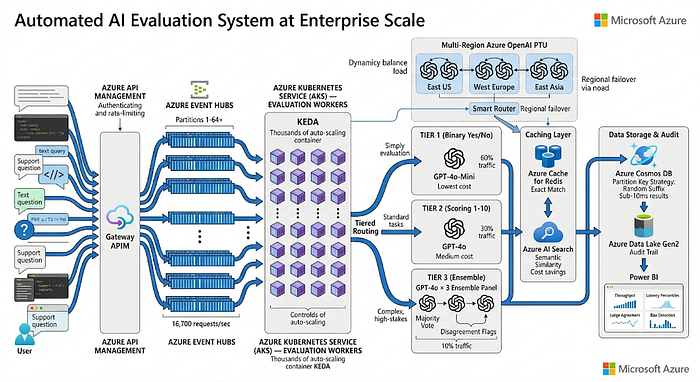
TL;DR: Researchers tested 20 AI models as judges. 17 out of 20 were statistically biased. True negative rate: 42.5% — your judge misses bad output more than half the time. If you have an LLM checking another LLM's work, this is your problem.
You probably have this in production right now.
response = await generator.chat(user_query)
review = await evaluator.chat(f"Rate this response 1-10: {response}")
if review.score >= 7: