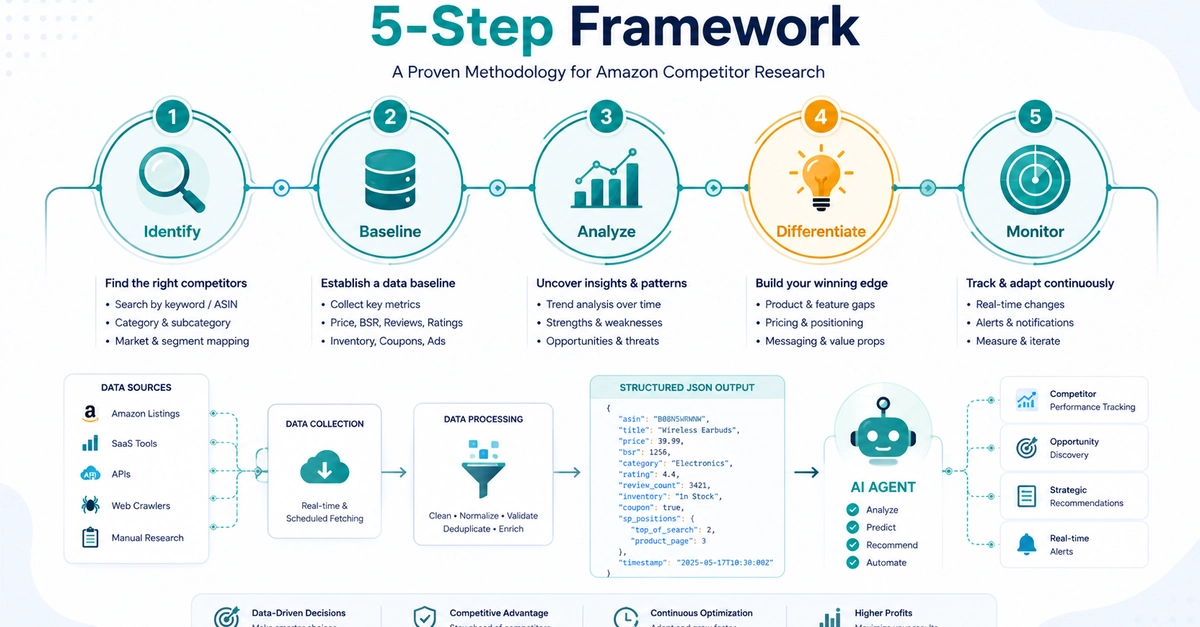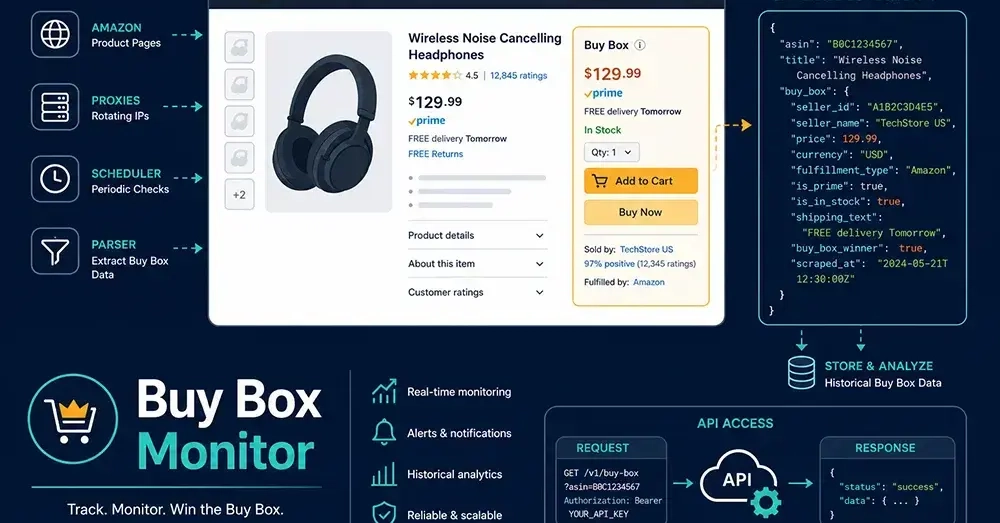
TL;DR: Amazon's Buy Box data requires JavaScript rendering—standard HTTP requests won't work. DIY Playwright scrapers fail at scale (35–55% success rate in 2026 conditions). Pangolinfo Scrape API is the production path: >95% success rate, structured JSON output, 5–15 min freshness. Complete working code below.
Why This Is Harder Than It Looks
Before writing any code, there's an architectural reality to understand: Amazon's Buy Box data isn't in the HTML.
The #buybox DOM section on Amazon product pages loads via async JavaScript—roughly 800ms–2s after the initial page shell. Any approach using requests, httpx, or urllib will retrieve an empty container. The seller name, price, and fulfillment type fields simply aren't present in the static response.
That's the baseline problem. The harder challenge is Amazon's anti-scraping stack: