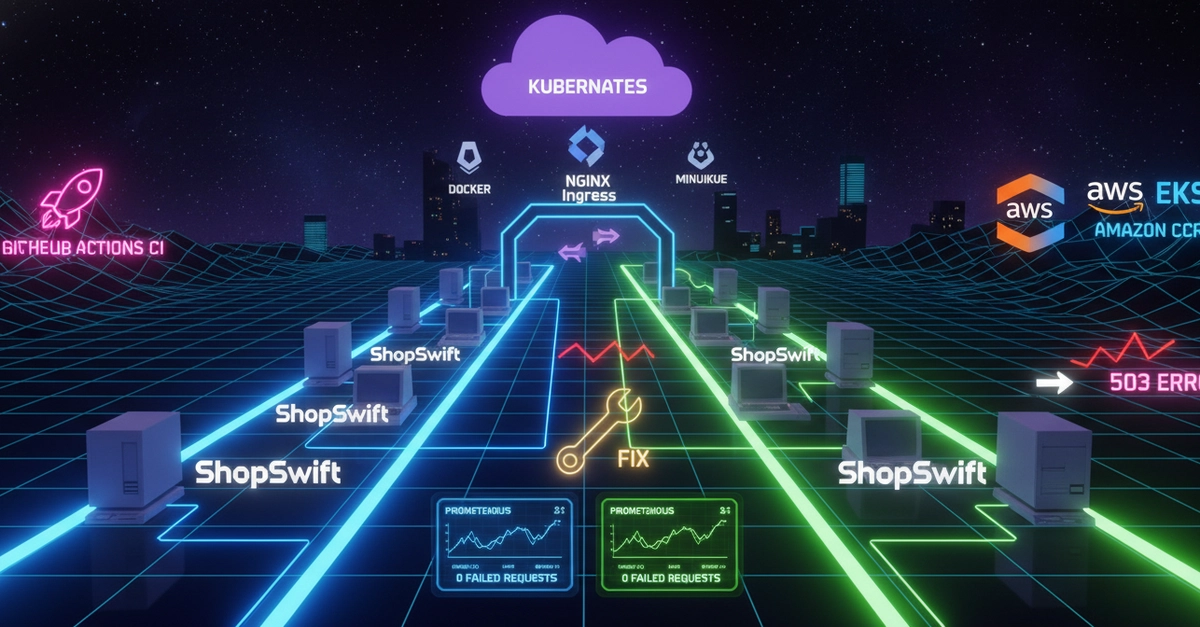
I built ShopSwift, a Node.js/Express e-commerce API, and wrapped it in a production-grade blue-green deployment pipeline: Docker, Kubernetes, Minikube local validation, NGINX Ingress, GitHub Actions CI, AWS EKS, Amazon ECR, and Prometheus + Grafana monitoring. Zero failed requests across every switch and rollback. Here is exactly how I did it - including the architecture mistake that caused a 503, and the fix that made it truly zero-downtime.
The Real Problem With Shipping Software
Releasing code is where theory meets reality.
A feature can pass every local test, build cleanly in CI, and still fail the moment real traffic touches it. When it does, the question is not what broke - it is how quickly can you recover without taking users down with you.
Traditional rolling deployments reduce this risk but do not eliminate it. During a rollout, old and new code can run simultaneously, creating version skew. If the new version is bad, rollback means redeploying the old one - which takes time users will feel.