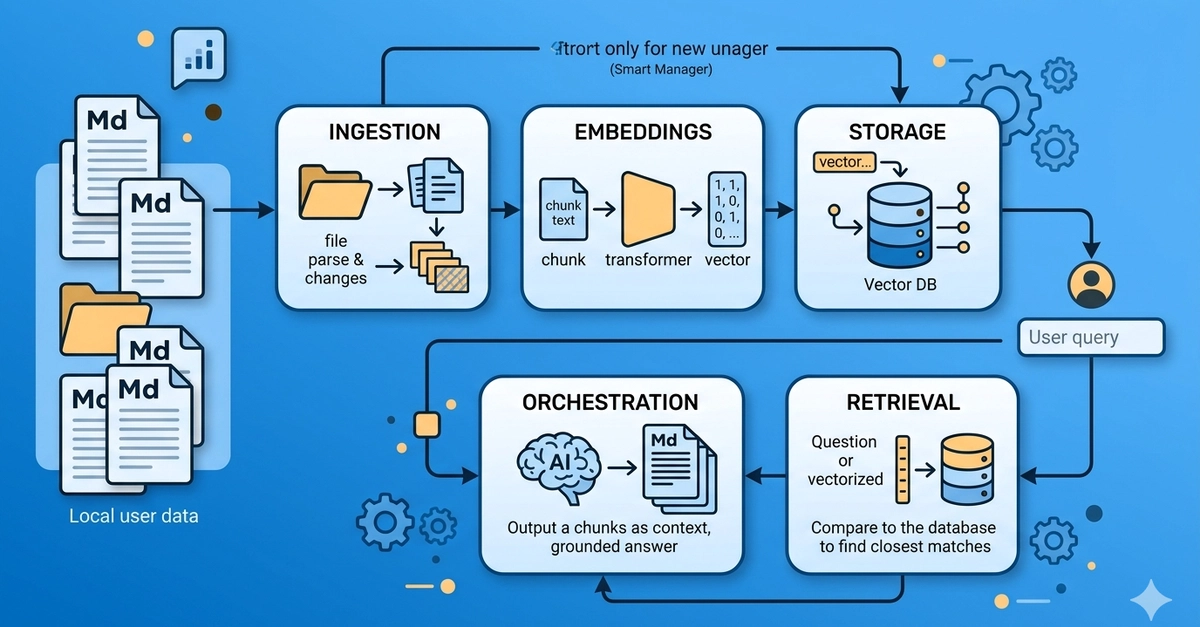
pluckmd exists so an agent can pull blog posts into markdown, index them into a wiki, and generate interactive HTML to learn from. This post is about the first step, the part with no per-site code, because the design is the interesting bit.
If you want the practical side, how I actually use it day to day, I wrote that up separately: https://dev.to/taisei_ide/how-i-use-pluckmd-to-read-blogs-with-an-ai-agent-1jpe
It downloads articles from a blog without any per-site code. No handler for Medium, no handler for Substack, nothing keyed on a domain. Here's how that works.
The core idea: treat extraction as data, not code.
AdapterSpec