Every data pipeline eventually needs a bucket. Then a second bucket. Then a BigQuery dataset, a service account with the right permissions, and a Lambda function to handle alerts. If you set all of that up through the GCP and AWS consoles, you get something that works once, is impossible to reproduce exactly, and will be misconfigured in the next project because you forgot which checkboxes you ticked. Terraform solves this by treating infrastructure as code: version-controlled, reviewable, and repeatable.
This article covers the patterns a data engineer actually needs. Not VPCs and Kubernetes clusters. GCS buckets, BigQuery tables with partitioning, S3 data lakes with lifecycle rules, Lambda functions for lightweight processing, and the IAM wiring that makes service accounts work without over-permissioning.
All provider versions in this article are current as of June 2026: Terraform 1.15.5, Google provider 7.34.0, AWS provider 6.47.0.
The Mental Model: State, Plan, Apply
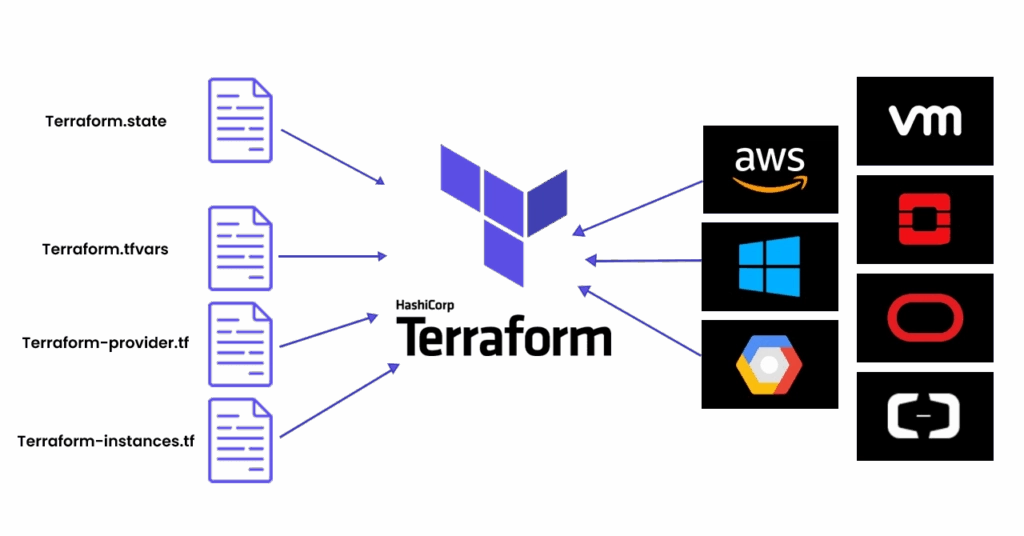
Terraform works by comparing three things: what you wrote in your .tf files, what it last recorded in the state file, and what actually exists in the cloud. The core workflow is three commands: