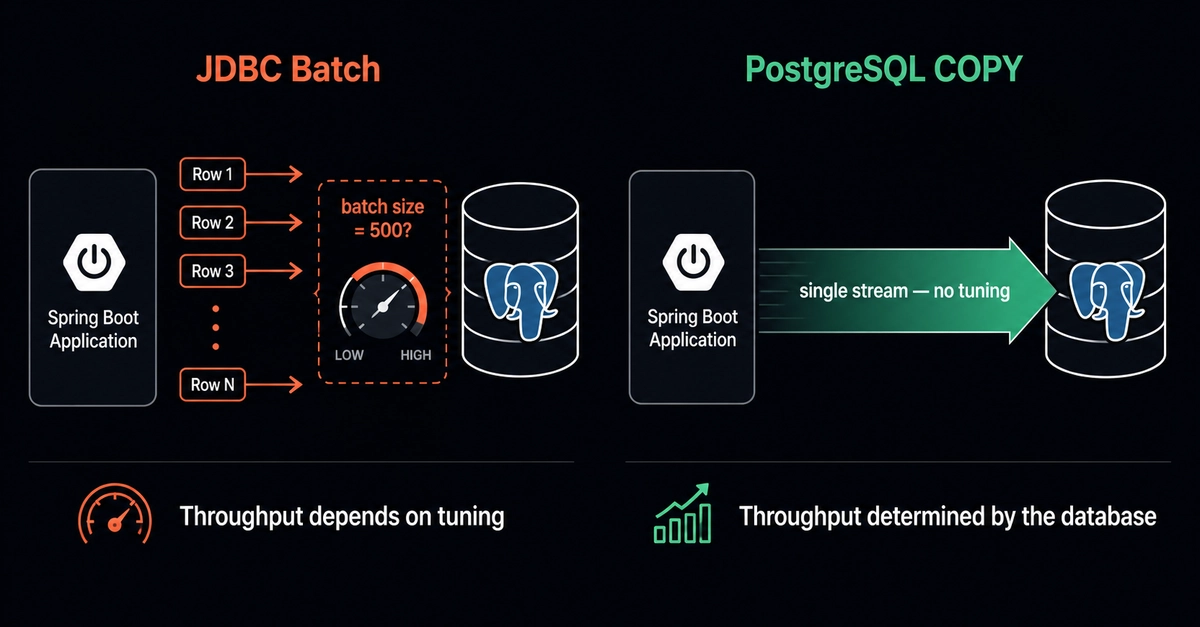
The LedgerSync pipeline was inserting 1.5 million rows into PostgreSQL using pandas.to_sql(). It took four minutes per run. I switched to psycopg2's COPY command and it dropped to 18 seconds. Same data, same schema, same machine. That is not an optimization tip. It is the difference between a pipeline that fits in an Airflow schedule and one that does not. This article is about patterns like that: the ones that matter when you are building pipelines that run on a schedule, not when you are writing ad-hoc queries.
Loading Data: to_sql vs execute_values vs COPY
There are three ways to write rows from Python into PostgreSQL, and the performance gap between them is significant.
pandas to_sql issues one INSERT statement per row by default, or a multi-row INSERT with method="multi". It is the easiest to write and the slowest for any serious volume.
psycopg2 execute_values batches many rows into a single multi-row INSERT VALUES statement. About 5x faster than to_sql for medium-sized loads.