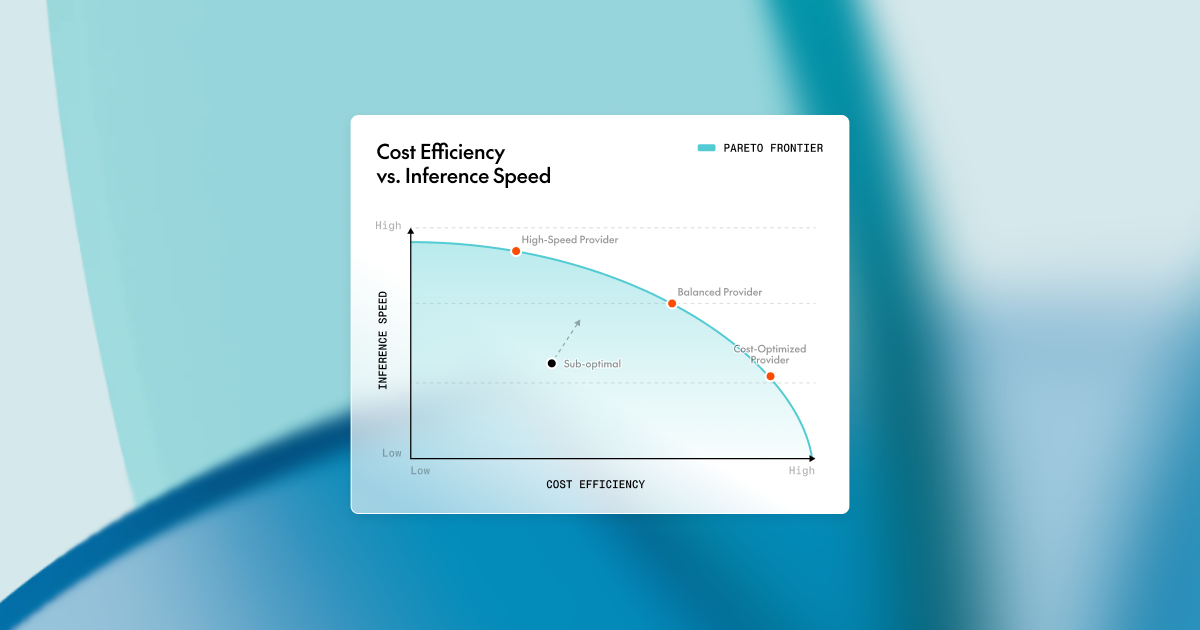
I've been running AI infrastructure for startups long enough to know one painful truth: when you're iterating fast, GPU costs will eat your runway before your product finds product-market fit. Last quarter alone, I watched a promising seed-stage company burn through $12,000 on self-hosted inference before they had 100 paying users. That's not scale — that's a funeral.
Let me share what I've learned about making open-source models production-ready without bleeding cash. This isn't theory. This is what I've deployed across three startups, and it's saved us roughly 70% on inference costs while keeping our iteration speed at hyperscale.
The Real Cost of Self-Hosting (Spoiler: It's Not Just GPUs)
Here's the thing nobody tells you about self-hosting. The GPU rental is just the headline number. The real cost — the one that kills startups — is the hidden infrastructure tax.
Model