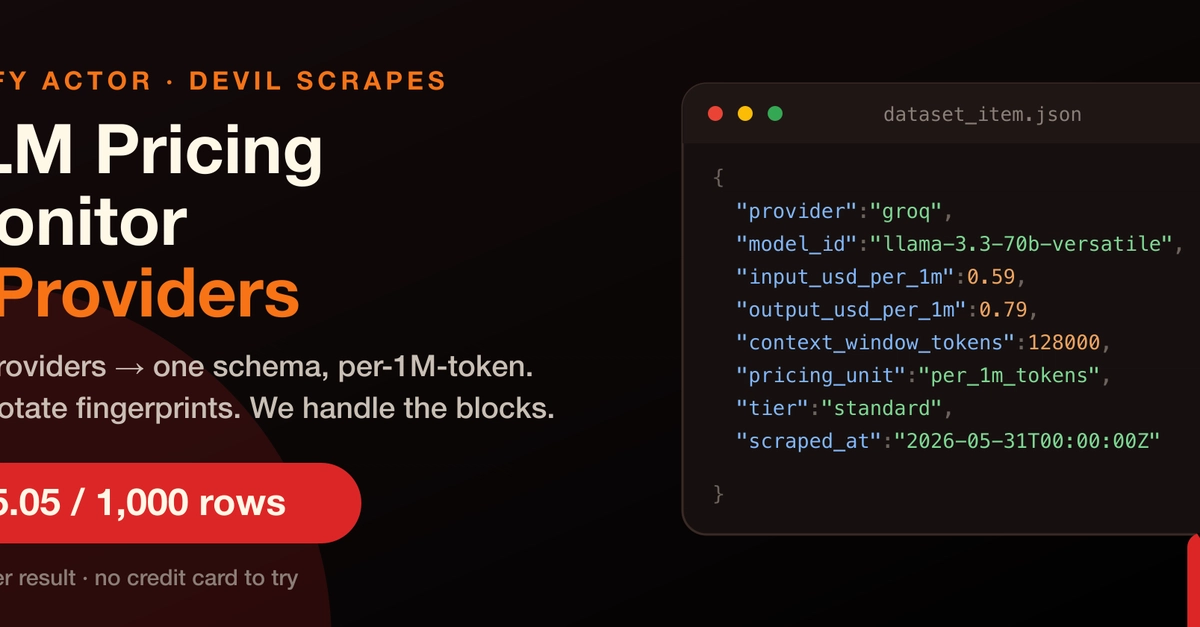
Quick answer: There is no unified official API for LLM pricing. OpenAI, Anthropic, Google, Mistral, Groq, Together AI, and DeepSeek each publish their prices in a different format — Webflow pages, Next.js RSC payloads, Docusaurus markdown tables, Cloudflare-protected SPAs. The LLM Pricing Monitor Apify Actor scrapes every one of them in a single run and emits a unified per-million-token dataset. One row per (provider × model × tier), validated with Pydantic, for $0.005 per row — roughly $5.05 per 1,000 rows.
Every few months someone tweets a screenshot comparison of GPT-4o vs Claude vs Gemini pricing. Within 72 hours it's stale — one provider dropped a batch discount, another renamed a tier, DeepSeek cut prices in half again. The screenshot keeps getting shared after the numbers are already wrong.
If you're building a cost-aware LLM router, a FinOps dashboard, or just answering "which provider is cheapest for 128k-context workloads right now", you need live numbers. Here is what fetching them programmatically looks like, and why it takes more than a few requests.get() calls.
What is LLM API pricing? 🔎
LLM API pricing is the per-token fee each inference provider charges to run a language model via their API. The industry converged on a rough standard: you pay separately for input tokens (your prompt) and output tokens (the completion), quoted in USD per 1 million tokens. Some providers also publish separate prices for cached input reads, cache writes, and batch API runs that can be 50% cheaper than the standard path.