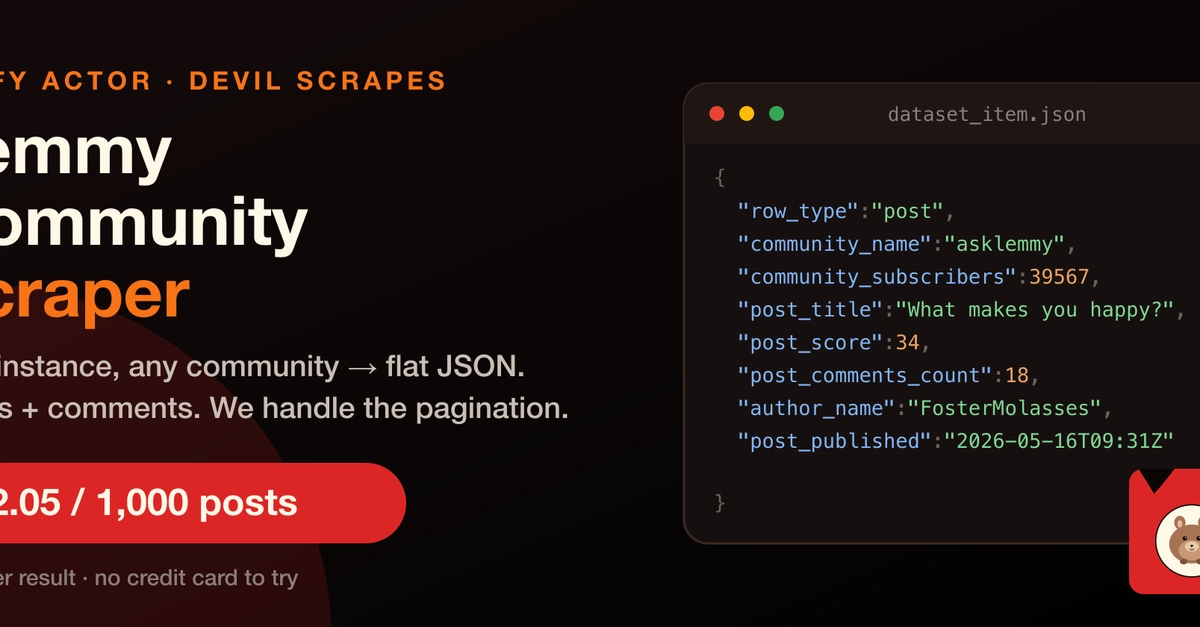
Quick answer: A Lemmy scraper calls the public /api/v3/ REST API that every Lemmy instance exposes by design and returns posts (and optionally comments) as flat JSON rows. The Apify Actor below handles cursor pagination, exponential backoff on rate limits, browser fingerprint rotation, and denormalised output — one row per post or comment, community metadata included. Cost: $0.002 per post row, $0.001 per comment row, $0.05 per run start (~$2.05 per 1,000 posts).
When Reddit tightened its API terms in mid-2023, a wave of communities migrated to Lemmy. Three years later, lemmy.world hosts more than 39,000 subscribers in c/asklemmy alone, alongside dozens of active instances — lemmy.ml, beehaw.org, sh.itjust.works, programming.dev — each running the same open-source software and the same versioned REST API. For researchers, journalists, and NLP engineers, Lemmy is Reddit-shaped conversation data without the OAuth application process or the restricted academic access tier.
The complication: "same API" still means cursor-based post pagination, integer-page comment pagination, a 17-token sort enum that changed between minor versions (bare Top was silently removed in v0.19), and a federated post model where the post_ap_id field points back to the originating instance — not the one you queried. We absorb all of that for you.