Two weeks ago CodeGraph hit GitHub trending — tree-sitter + SQLite/FTS5 + MCP for Claude Code, 19k+ stars in a week. The team published a benchmark on 7 repos showing 35% cheaper, 57% fewer tokens, 46% faster, 71% fewer tool calls vs. baseline.
Those are big numbers. They're also numbers from a benchmark designed by the team that built the tool, on repos they chose. Designer bias is the #1 risk in any retrieval benchmark — when you pick the test repos and write the ground truth, you'll consciously or unconsciously favor your own tool's strengths.
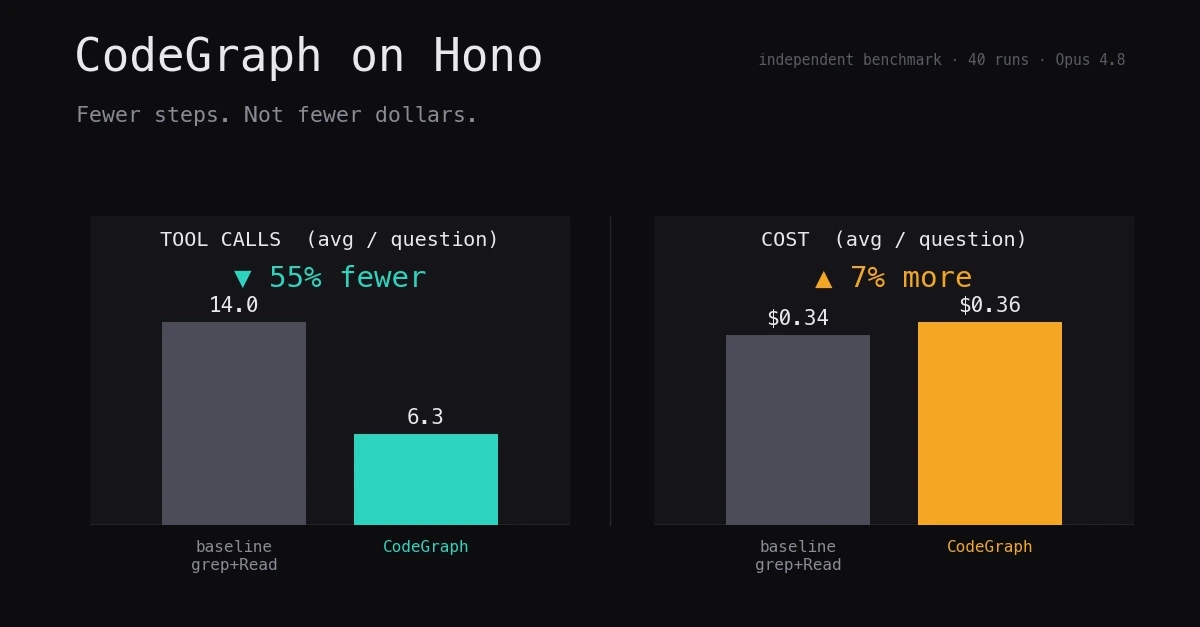
So I ran an independent test on an 8th repo — Hono (TypeScript, ~280 source files, in neither CodeGraph's published 7-repo suite nor any other published benchmark I could find). 5 architectural questions covering different retrieval shapes, with a deliberate control case (Q5) where the tool should not win. Two conditions (baseline grep+Read+Glob+Explore vs. CodeGraph active), 4 repeats per question per condition. 40 runs on Claude Opus 4.8 — and, critically, every CodeGraph run was verified to have connected, and actual codegraph_* tool usage was recorded per run (more on why that sentence exists below).
The result splits in a way the single published headline number hides — and the split is the useful part.