TL;DR
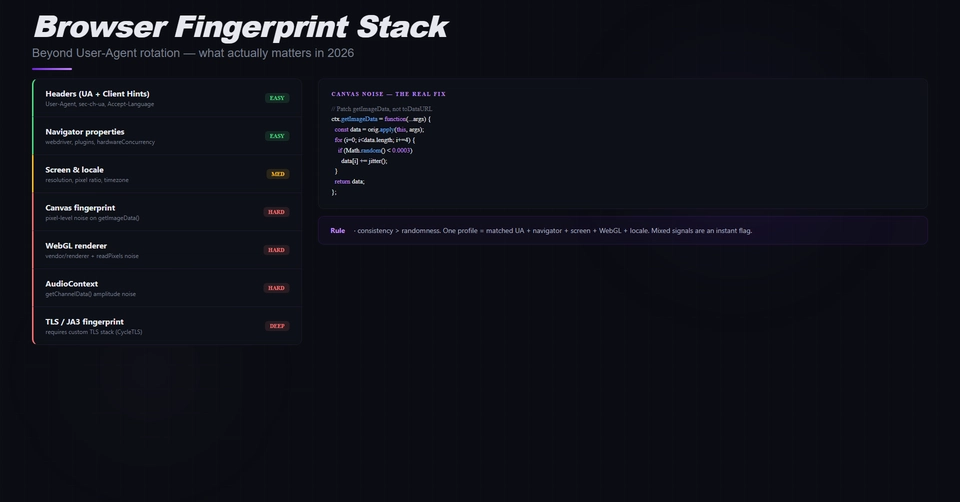
To build reliable AI data extraction pipelines, you must align your IP reputation with realistic browser fingerprints. This means rotating IPs intelligently across subnets, neutralizing TLS and JavaScript-based fingerprinting vectors like Canvas and WebGL, and executing headless browsers only when DOM rendering is strictly required.
The State of Data Extraction Infrastructure
AI agents and Large Language Models (LLMs) depend on massive volumes of structured text. When building Retrieval-Augmented Generation (RAG) pipelines or market intelligence tools, stale datasets degrade model output. You need fresh, real-time public data.
Extracting this data at scale is an infrastructure problem. Modern web infrastructure aggressively filters automated traffic. Sending basic requests.get() calls from cloud provider IPs will result in immediate blocklists. To maintain access to public data, your extraction pipeline must replicate the network behavior and hardware signatures of legitimate users.