Overview
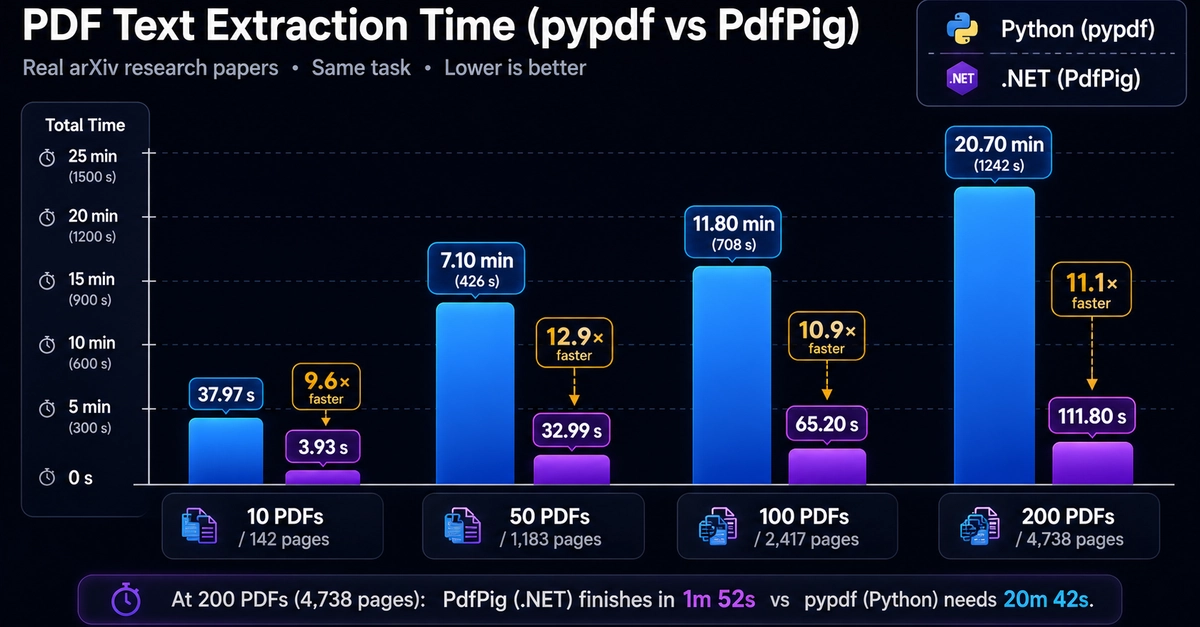
PDF text extraction is a common pre-processing step in data pipelines — ingesting research papers, legal documents, or reports before embedding or indexing. Both pypdf and PdfPig are pure managed-code parsers: no native binaries, no OCR, no system PDF renderer. They implement the same PDF specification operations in their respective languages.
This makes the benchmark unusually clean: the performance difference is entirely due to language execution speed, not library architecture differences.
Benchmark Setup
200 recent arXiv PDFs (mixed technical papers, 5–40 pages each). Tested on subsets of 10, 50, 100, and 200 files. Both libraries extract all text from all pages; output is validated for page-count agreement and character-count agreement within 15% (pypdf and PdfPig decode whitespace and encoding tables slightly differently).













