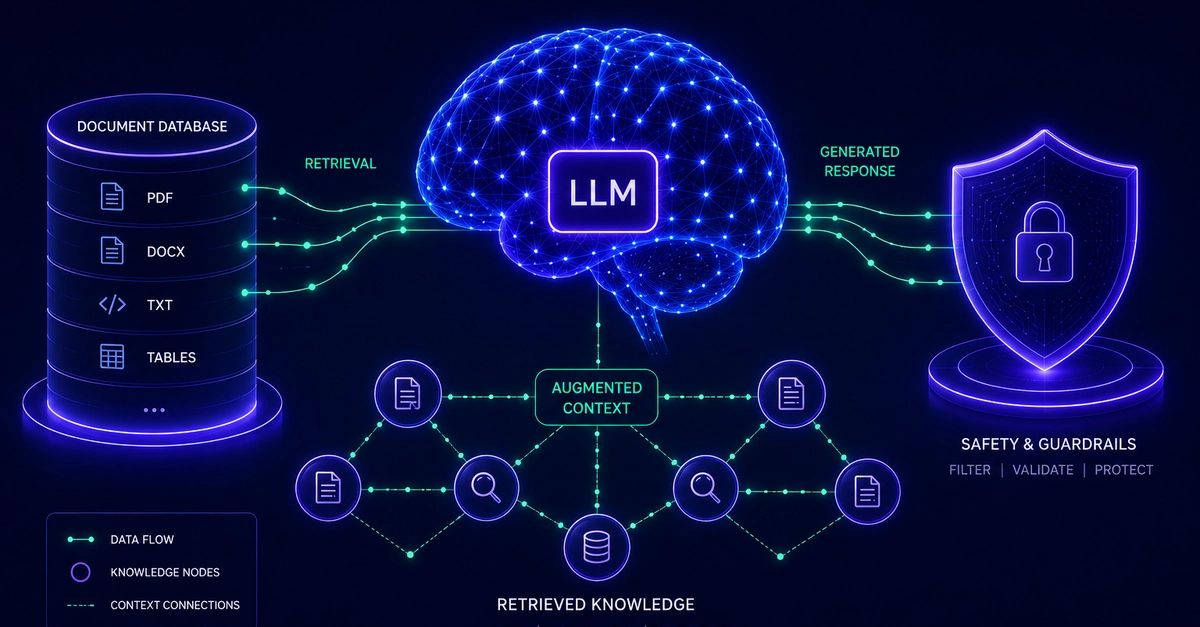
A complete hands-on guide to building Retrieval Augmented Generation on AWS Bedrock with pgvector, Guardrails, Prompt Management, Knowledge Bases, Evaluations and API Gateway
What You Will Build
A production-shaped Retrieval Augmented Generation (RAG) system on AWS Bedrock that a real engineering team could deploy. By the end of this guide you will have:
Documents ingested into Aurora Serverless v2 with pgvector via Titan Embeddings v2
Semantic search over your document corpus using HNSW vector indexing