Why the obvious approach crashes, and how a few generator functions keep memory flat no matter how big the file gets.
A while back I had to do something that looked trivial on paper. Read a CSV export, filter the rows we cared about, sum one column, write a small report. The kind of thing you bang out in ten minutes. The file was around 2GB.
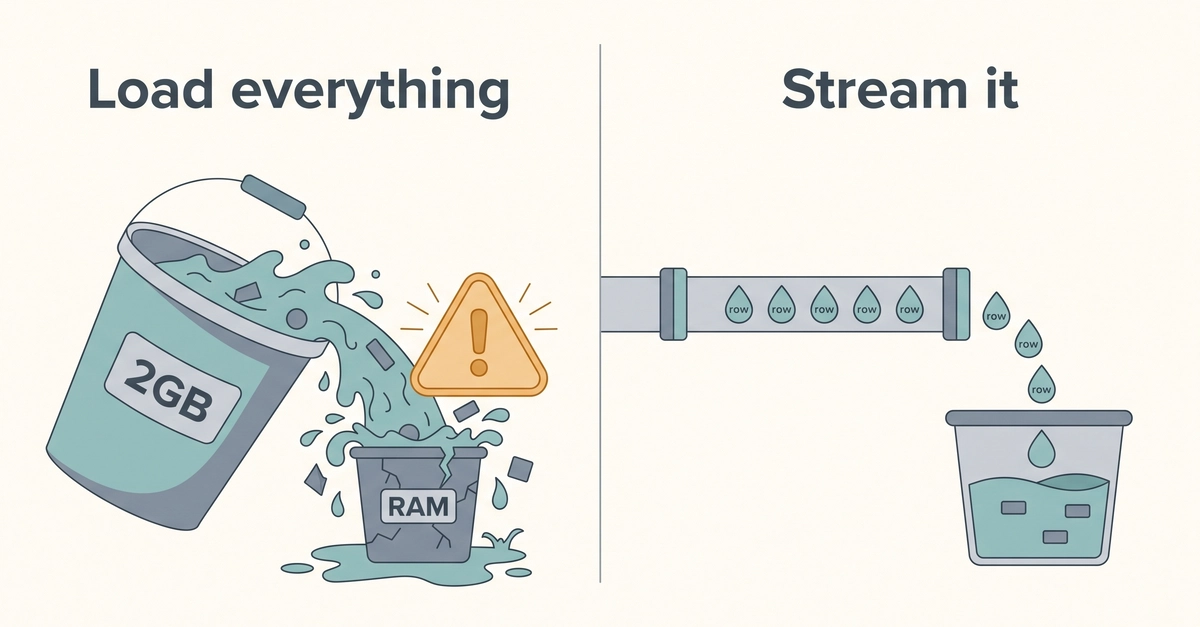
The first version was four lines. It worked great on the 5MB sample. Then I pointed it at the real export and Node fell over with JavaScript heap out of memory. So I did what we all do, bumped --max-old-space-size, gave it more heap, ran it again. It got further and died again. That was the moment I stopped fighting the symptom and looked at what the code was actually asking the machine to do.
Here is the thing that took me some time to internalize: the size of your data does not have to dictate the size of your memory footprint. You can process a file bigger than your RAM. The trick is to never hold the whole thing at once, and generators give you a clean way to write code that does exactly that without turning into a mess of callbacks and manual state.
Let's build up to it properly.





