When a deal closes in your CRM and a contract still needs a human to open Word, paste in the account name, and adjust the pricing table, you have a document generation problem. The mechanism for solving it is well understood: a rendering engine resolves a template against a structured data payload and emits a finished file. What most guides skip is the implementation layer that determines whether the system survives an audit, scales past the first team that uses it, and stops requiring developer time after launch. That means credential handling, data residency, compliance certifications, and the build-vs-buy threshold for the rendering layer itself.
This article covers the architecture and the hard decisions. The "what is document generation" recap is intentionally short so the security, compliance, and decision-framework content has room to breathe.
Document Generation: The Core Mental Model
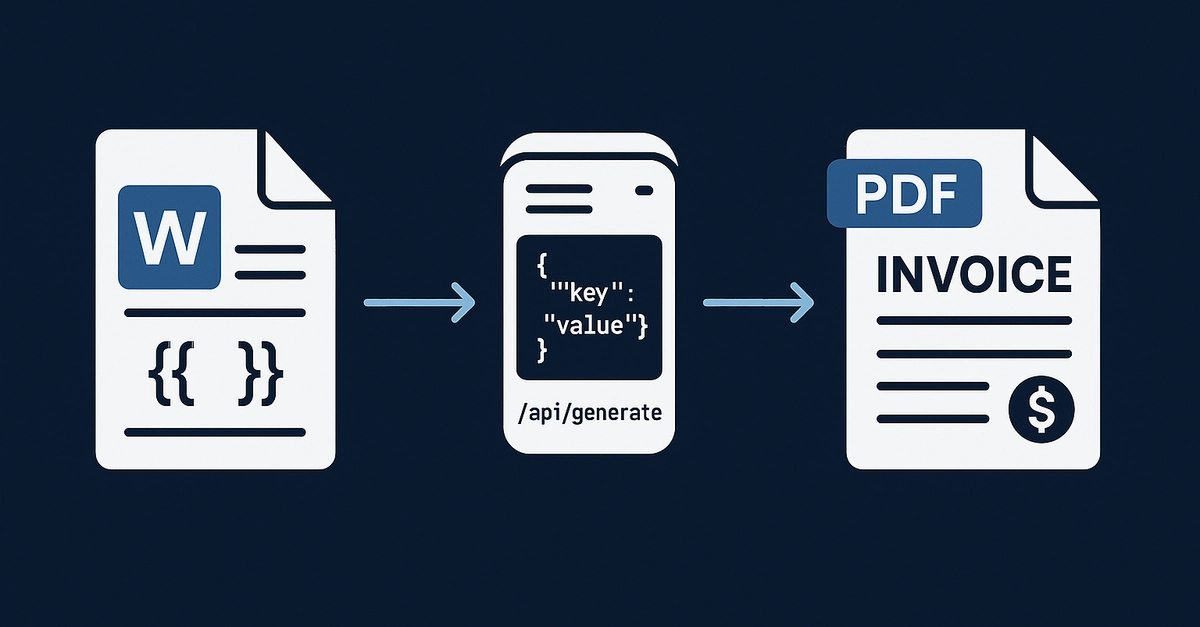
A document generation system does one thing: it takes a template (structural layout, fixed text, placeholders) and a data payload (field values for those placeholders), merges them in a rendering engine, and produces an output file.
Three adjacent concepts get conflated with document generation frequently enough to distinguish here. Document editing puts a human in the loop to modify content interactively. Document management handles storage, versioning, and retrieval of existing files. PDF form-fill annotates existing form fields with values without regenerating the document structure. Generation produces a net-new file on each call.