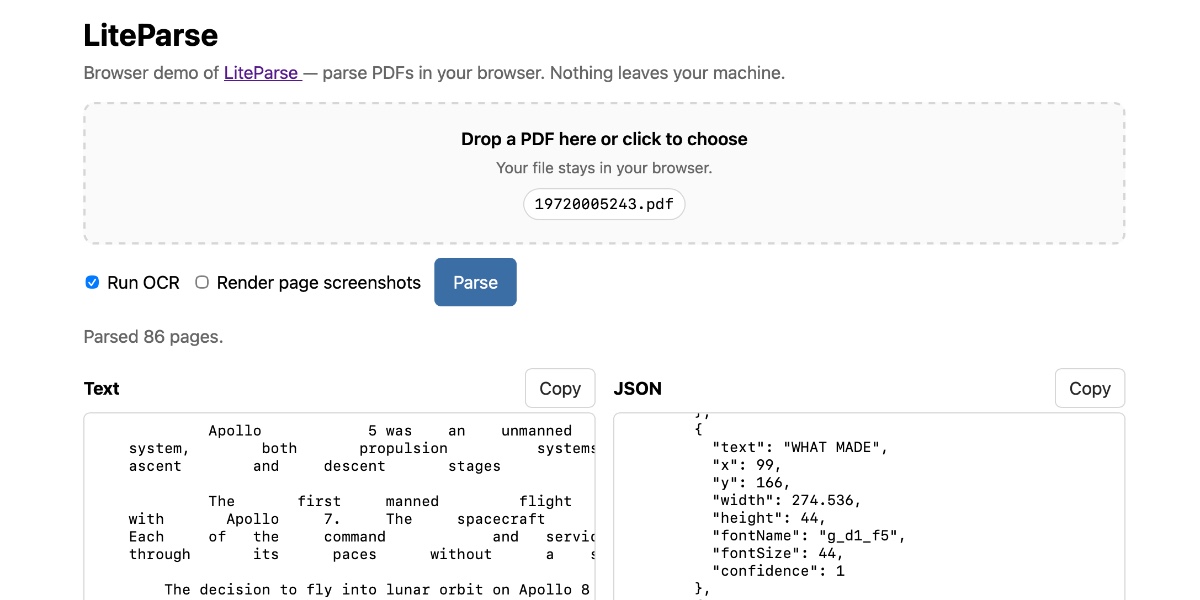
Browser-based PDF processing is a performance minefield. When you attempt to extract high-resolution images from a multi-page PDF document entirely on the client side, you are essentially asking your user's browser to juggle memory allocation and CPU cycles in a single-threaded environment. It is the classic recipe for a frozen UI, a frustrated user, and a heap memory overflow that crashes the tab instantly. I have spent countless late nights fighting with bloated vendor libraries and inefficient loop patterns, trying to prevent that dreaded browser 'Aw, Snap!' page. Today, we are going to dive deep into how to build a performant, non-blocking pipeline for PDF image extraction without resorting to expensive server-side conversion backends.
The Problem: The Hidden Cost of Client-Side PDF Parsing
The fundamental issue stems from how browsers handle heavy processing. JavaScript, for the most part, runs on the main UI thread. When you initiate a massive blob decoding operation or heavy bitmap manipulation for PDF assets, you effectively pause the main thread. This means no event loops, no scroll events, and no UI repaints. If the file is 50MB and contains complex vector rendering, your browser tab will stop responding entirely. Users perceive this as a frozen app, and their only recourse is closing the tab.