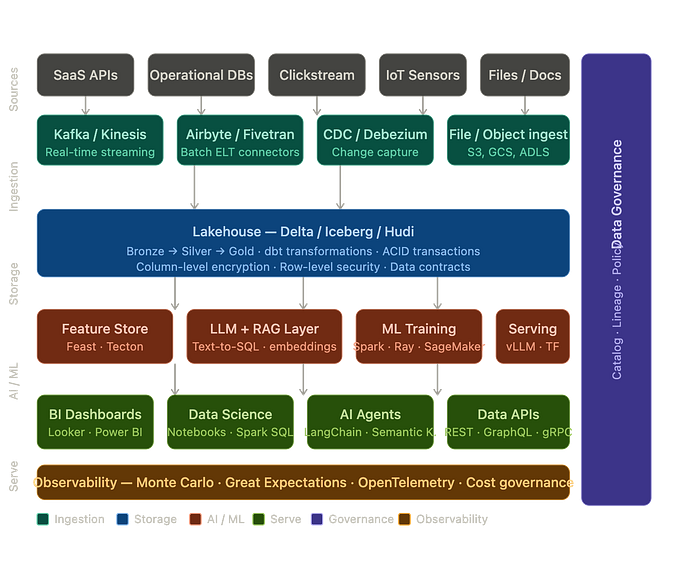
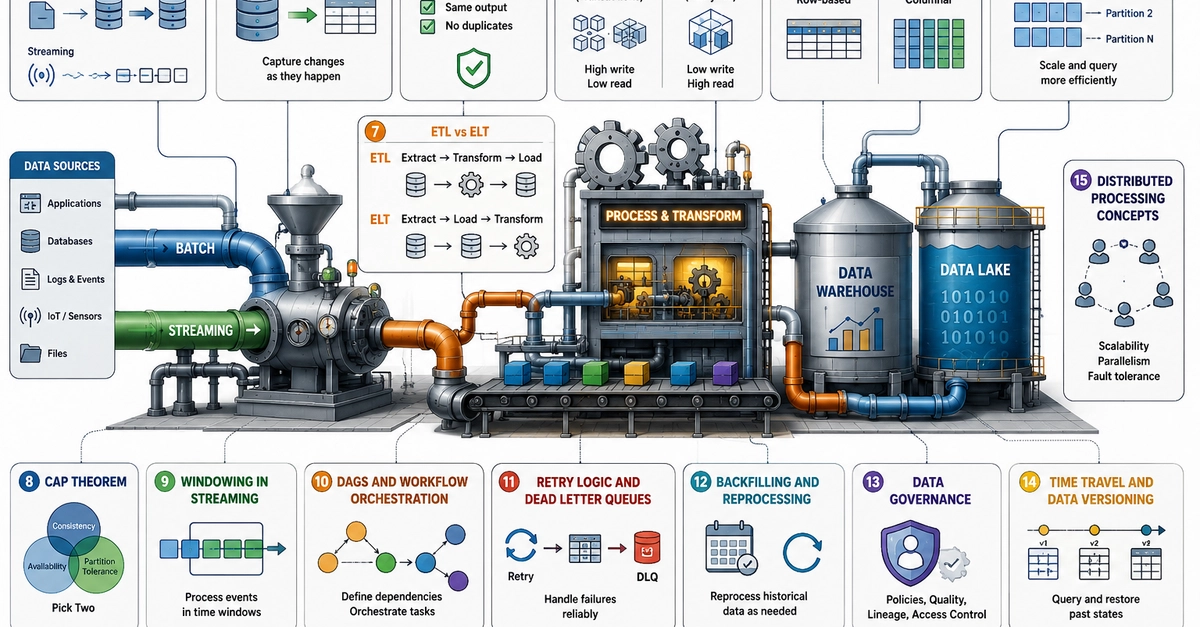
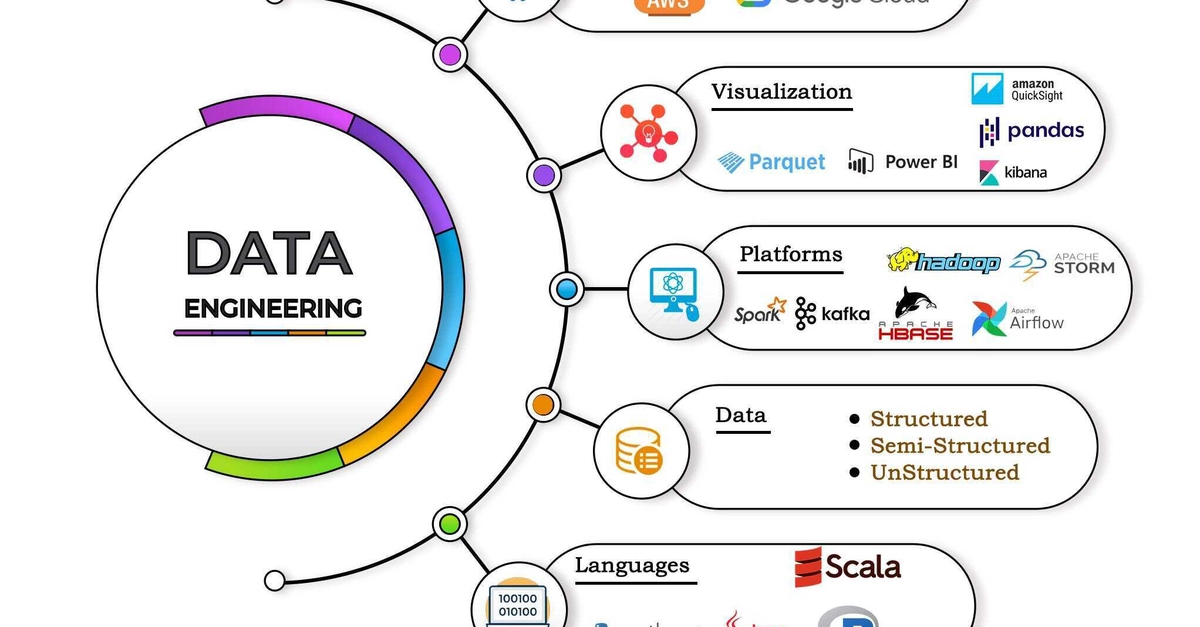
Over the past decade, the core evolution of data engineering has been the deconstruction and reconstruction of traditional data warehouse architectures through the Modern Data Stack.
We separated data ingestion from databases, forming the Data Ingestion layer, using tools like FiveTran, Airbyte, and Apache SeaTunnel to solve ELT / CDC / Reverse ETL problems;
We separated compute from storage, forming cloud data warehouse and lakehouse systems such as Snowflake, Databricks, Iceberg, and Hive;
We separated orchestration from scripts, leading to orchestration systems like Apache Airflow and Apache DolphinScheduler;
SQL development, data modeling, lineage, data quality, BI, and AI analytics were further split into independent tools.