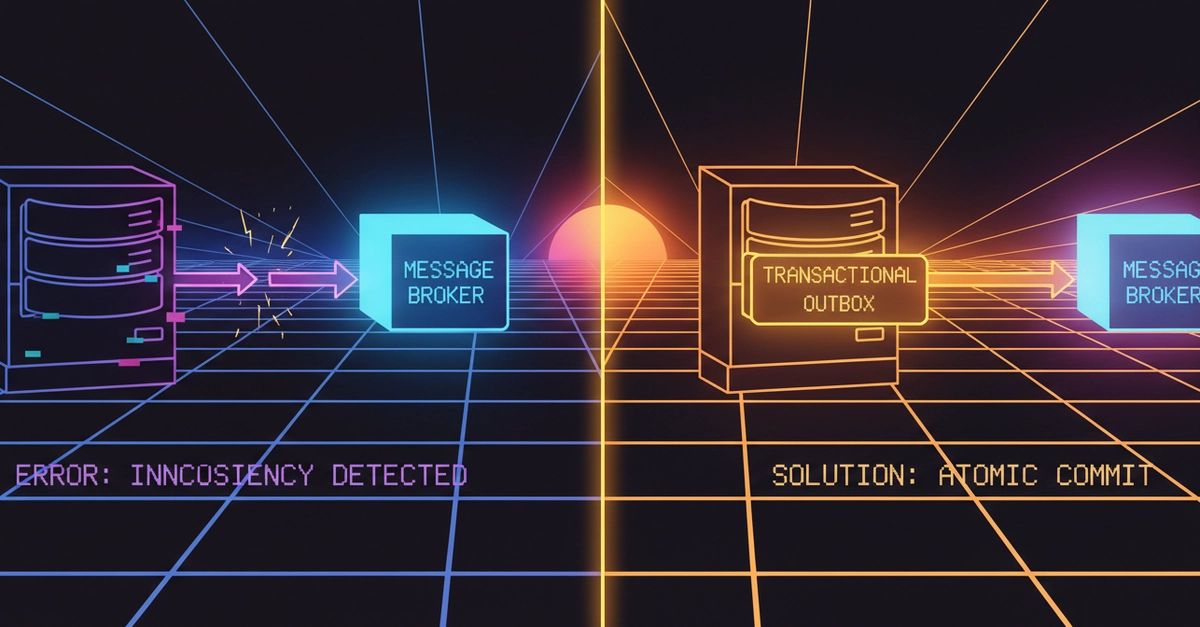
The Problem We Were Actually Solving
Our CQRS model kept Events in a separate Kafka cluster labeled event-store while Aggregates lived in PostgreSQL. The outbox pattern wrote Events to Kafka via Debezium, then the read side consumed them to build materialized views. The promise was eventual consistency with zero data loss. The reality was a 40-millisecond write path plus a 200-millisecond read path, and every time we scaled the read path the lag exploded because the offset commit cycle couldnt keep up with the volume. At 800 RPS the materialized views were 2.3 seconds stale; at 250k RPS the lag peaked at 4.2 million unprocessed events and the consumer restarted every 15 minutes with Zookeeper session timeouts. PagerDuty woke us at 3 a.m. for three nights in a row.
What We Tried First (And Why It Failed)
We tried three incremental fixes before we admitted the boundary was wrong. First, we upgraded Kafka to 3.5 with transactional producers, hoping idempotent writes would tame the lag. The lag dropped 12%—still 3.7 million unprocessed events. Second, we moved the read-side consumers to a tiered architecture with 12 k8s pods in three AZs. We saw CPU steal climb to 45% on the underlying nodes and the 99th percentile read latency increased to 900 ms. Third, we switched from Debezium to Kafka Connect with JDBC source, thinking schema evolution was our bottleneck. That introduced 20-second schema validation pauses and the lag climbed to 5.1 million events. Each attempt optimized one metric while breaking another; none touched the fundamental latency tax of crossing two databases and two networks.