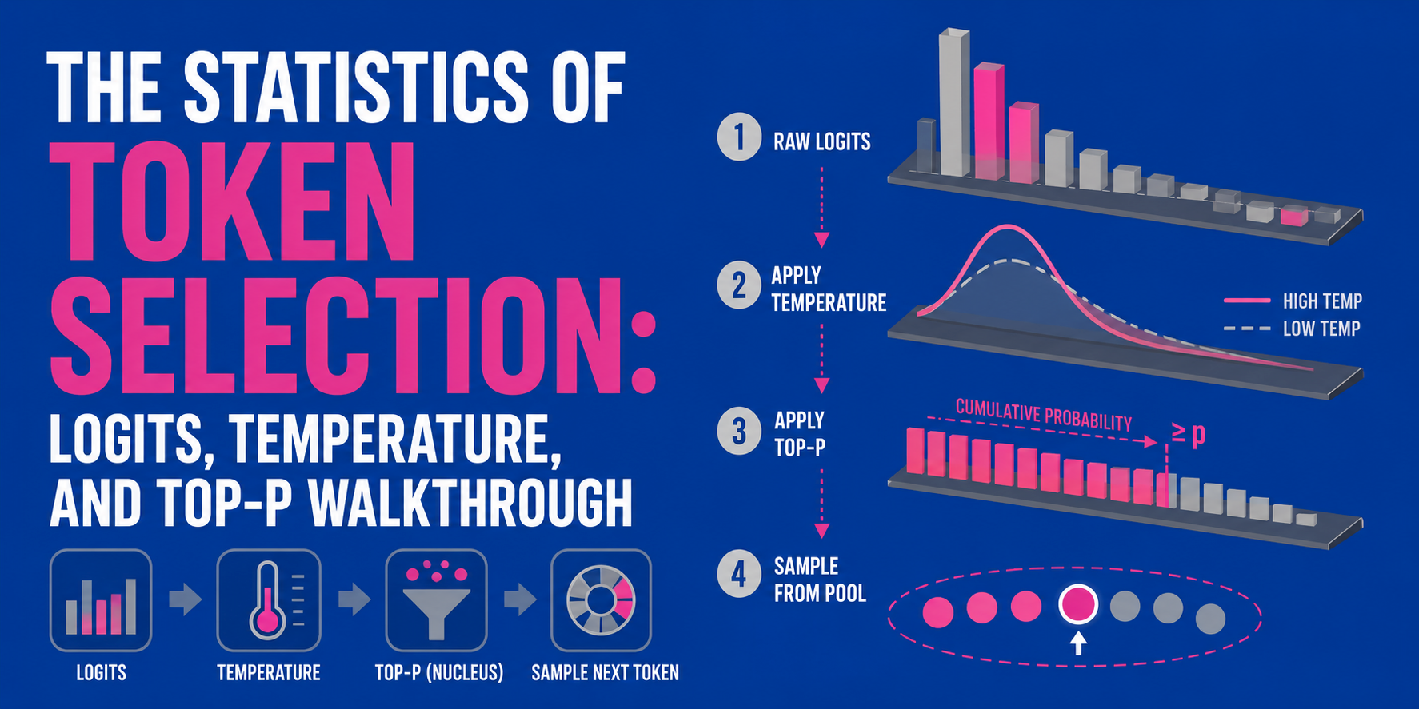
In this article, you will learn how logits, temperature, and top-p sampling work together to control next-token prediction in large language models.
Topics we will cover include:
What logits are and how they are produced by a transformer’s final linear layer.
How temperature and top-p (nucleus sampling) shape the probability distribution used for token selection.
How these three components fit into a sequential pipeline that governs LLM output generation.










