TL;DR: Most AI agent memory discussions still assume one agent talking to itself across sessions. But real coding workflows already involve Claude, Codex, Cursor, and Gemini touching the same repo in the same week. The hard problem is not "how does an agent remember." It is "how do multiple agents stay coordinated on the same project without stepping on each other." That problem does not live inside any one agent. It lives in the repo.
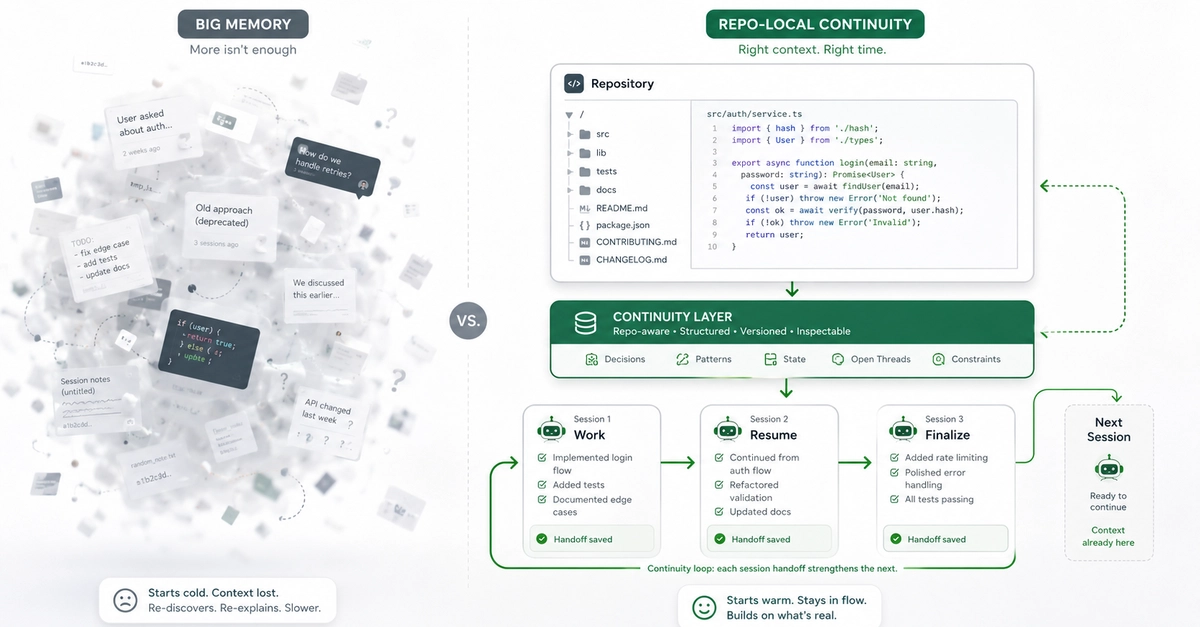
I wrote a post last week arguing that AI coding agent memory belongs in the repository, not the chat window. Checkpoints, not transcripts.
Sitting with that argument for a few days, I realized it is actually downstream of a bigger one I had not made explicitly yet. The checkpoint primitive only matters because of a problem the current agent stack does not have a name for.
So here it is.
The Industry Map Has A Blind Spot