TL;DR
In Part 1, Athena provided serverless read-only SQL. In Part 2, Databricks hit session policy boundaries. In Part 3, Snowflake works with config. In Part 4, DuckDB Lambda delivered the cheapest path. This Part 5 shows the full-power Spark ETL path with write-back.
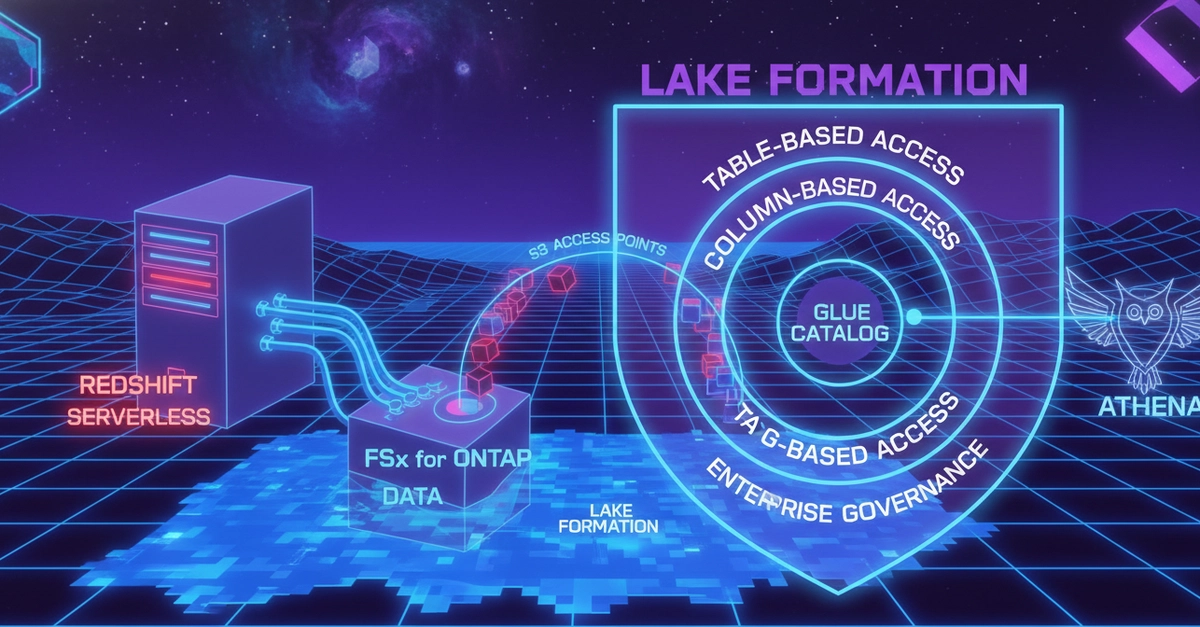
EMR Serverless Spark can read, transform, and write-back Parquet files on FSx for ONTAP via S3 Access Points. Total Spark execution: 16 seconds for a full ETL pipeline (read → aggregate → window → write). Job total including cold start: 37 seconds. Cost: ~$0.05 per job.
No cluster to manage. No data to copy. No idle cost.
Quick Decision Guide: