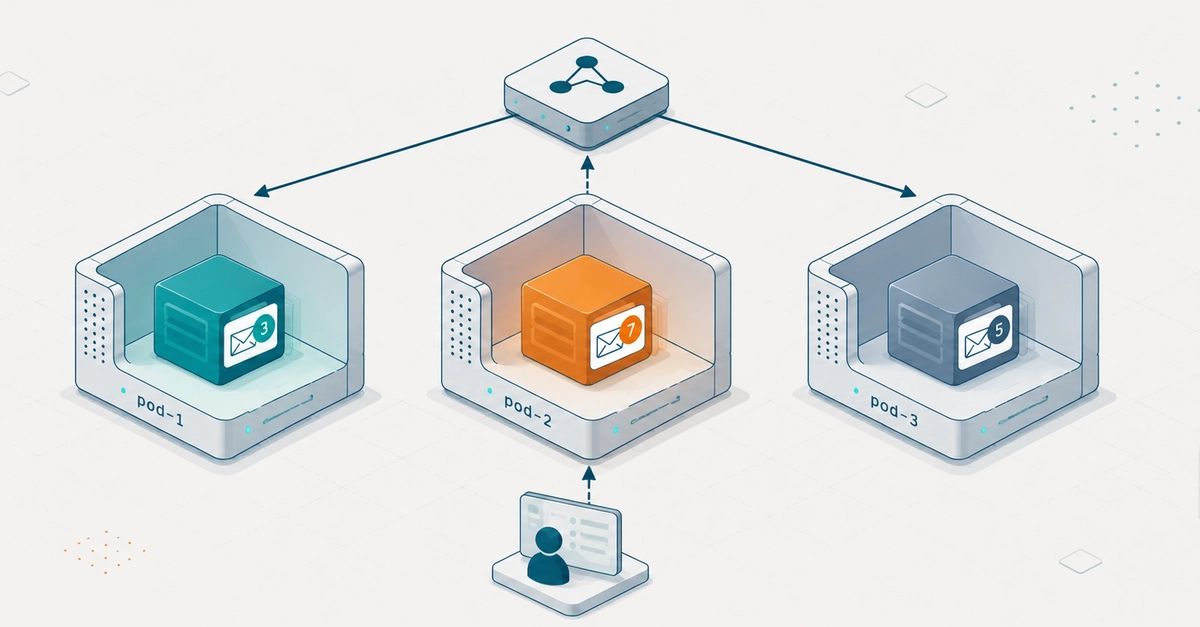
Você implementou um endpoint que busca a timeline de uma conversa, viu que a query era pesada demais pra rodar em todo request, então injetou um cache de memória no controller, configurou expiração de cinco minutos e seguiu a vida.
Nos testes e na homologação tudo se comporta como esperado: o primeiro request paga o custo, os seguintes voltam instantaneamente e o gráfico de latência fica bonito.
Aí o serviço entra em produção em um cluster Kubernetes com três réplicas, porque a empresa cresceu, porque o time finalmente migrou o monolito velho para um ambiente que escala horizontalmente, ou simplesmente porque o Tech Lead não quis mais depender de uma única instância.
E começam a chegar relatos estranhos:
o atendente atualiza a tela e vê a mensagem nova