I used to ship by faith. The change passed code review, the tests went green, the deploy button was right there, and I pressed it. Most of the time it was fine. The handful of times it was not fine cost me weekends, customer trust, and a real amount of money. The worst incident I can remember was a single line change that took down checkout for forty minutes during a marketing push. The change had passed every test we had. The bug only showed up under real traffic patterns.
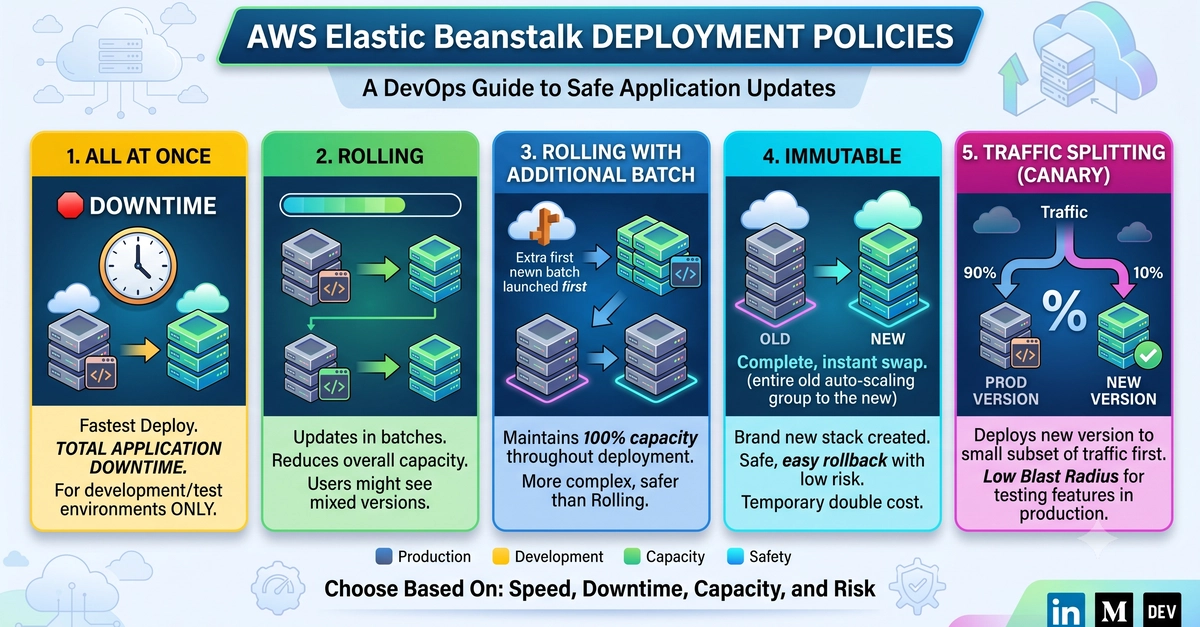
After that incident, I built a canary deployment workflow. Every risky change now ships to one percent of traffic first, sits there for a defined observation window, and gets promoted to the full population only when the metrics from the canary cohort look identical to the metrics from the control cohort. It works. The serious incidents I used to ship have been replaced by canary failures that get caught and rolled back before they reach the majority of users.
The hard part of canary deployment is not the routing layer. The routing layer is a solved problem. The hard part is everything around the routing layer: choosing the right metrics to watch, deciding what counts as a regression, building the decision logic that promotes or rolls back, and connecting it all to the deployment pipeline. That hard part is where Claude Code reshaped how I work. Here is the workflow.