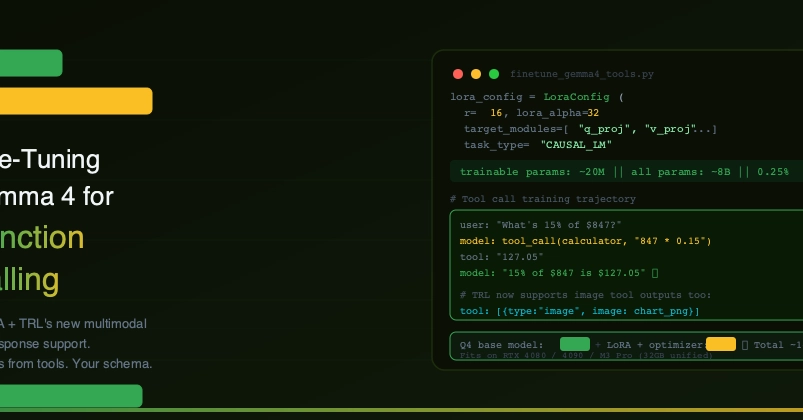
This is a submission for the Gemma 4 Challenge: Write About Gemma 4
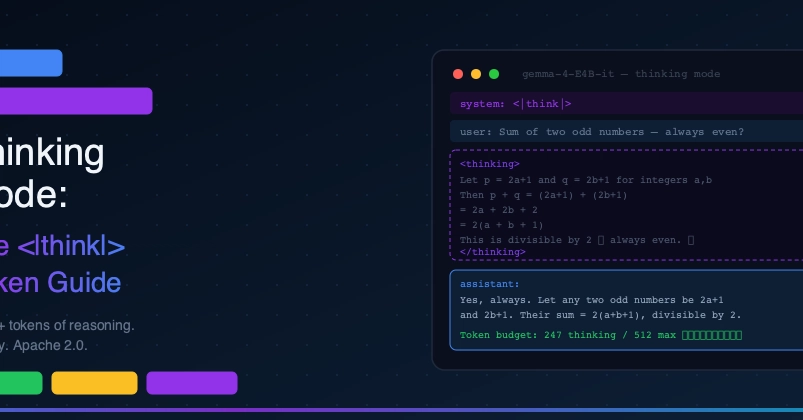
Gemma 4 ships with built-in reasoning — a configurable chain-of-thought that runs before the model gives you an answer. It's not a separate model, not a system prompt trick, and not a post-processing layer. It's a control token trained into the model from scratch.
Here's how to actually use it, when it's worth enabling, and how to tune the thinking budget so you're not burning 4,000 tokens on a yes/no question.
What Thinking Mode Is
When reasoning is enabled, Gemma 4 generates an internal chain-of-thought — up to 4,000+ tokens of "working out loud" — before producing its final answer. The reasoning tokens are visible in the output but clearly delimited, so you can surface them to users or strip them silently depending on your use case.