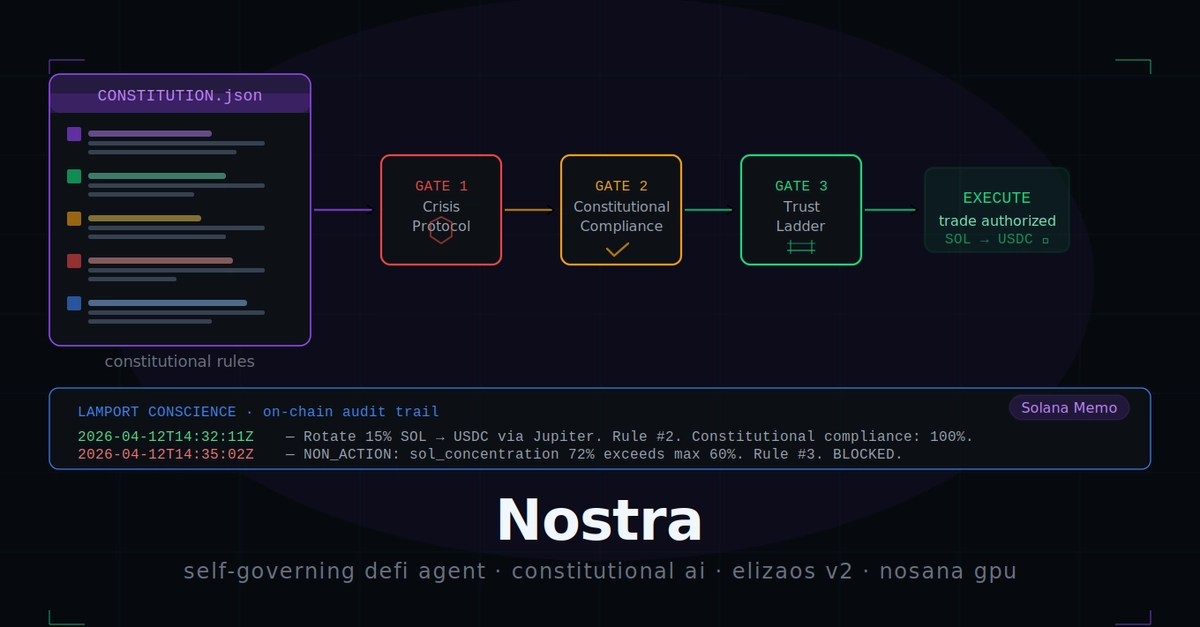
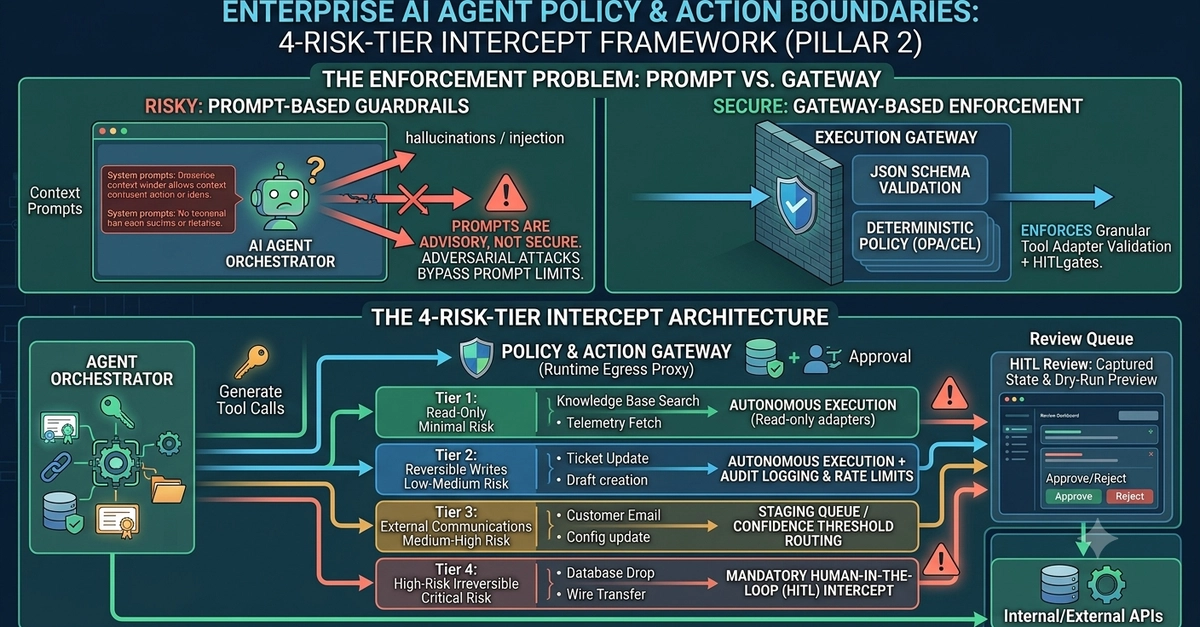
The Problem
You've built an autonomous AI agent. You've given it constraints—readonly rules it cannot modify. One rule might be: "Never auto-clear the human pause flag." Good. That prevents runaway behavior.
But now a legitimate edge case appears. The human explicitly grants authority for one specific action that would violate the constraint. The agent is stuck:
Option A: Read around its own doctrine (doctrine becomes meaningless)
Option B: Stay paralyzed (constraint defeats legitimate need)