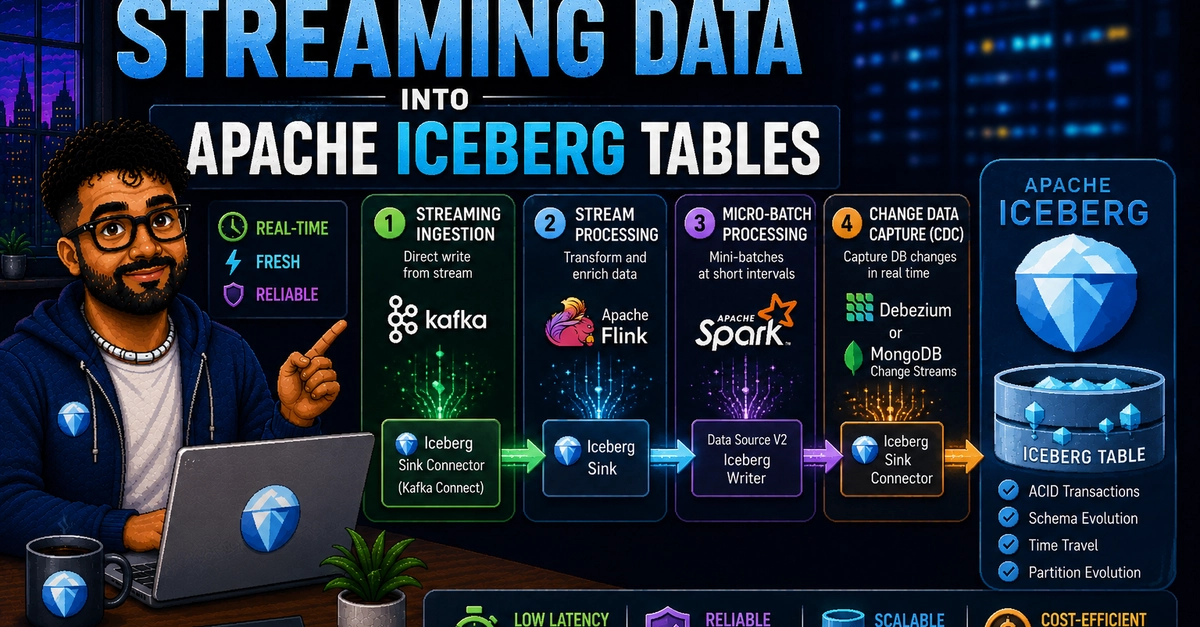
This is Part 13 of a 15-part Apache Iceberg Masterclass. Part 12 covered Python and MPP engines. This article covers the three primary approaches to streaming data into Iceberg tables and the operational trade-offs each creates.
Iceberg was designed for batch analytics, but most production data arrives continuously. Streaming ingestion bridges this gap by committing data to Iceberg tables at regular intervals. The challenge is that frequent commits create the small file problem, and managing that trade-off between data freshness and table health is the central concern of streaming to Iceberg.
Table of Contents
What Are Table Formats and Why Were They Needed?
The Metadata Structure of Current Table Formats






