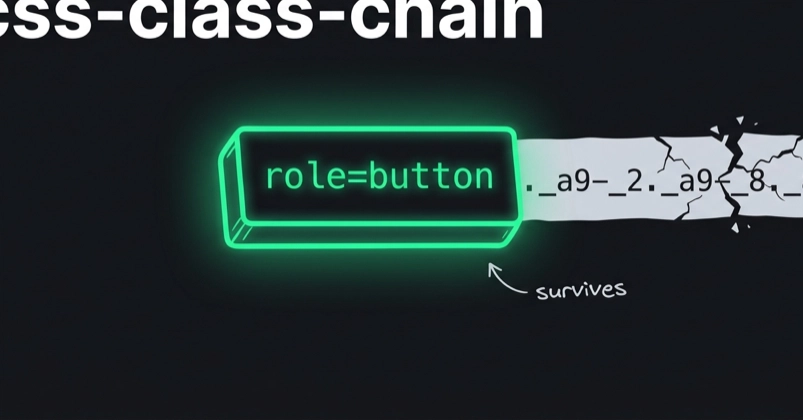
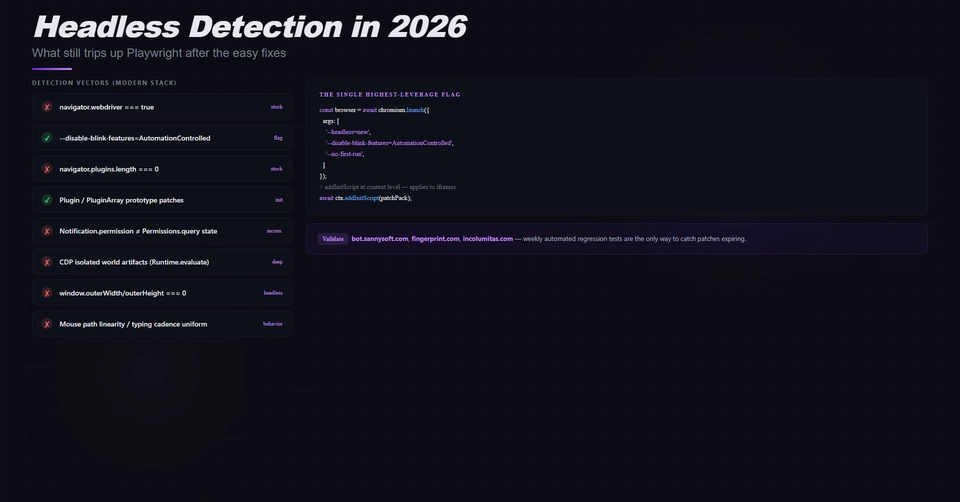
Most Playwright tutorials teach you to scrape a single page. Real scrapers need to scrape thousands. The thing that kills you isn't the selector — it's everything Playwright does before it touches the selector.
By default, Playwright loads a page like a human visiting a website. It downloads CSS, fonts, analytics scripts, A/B testing pixels, hero images, lazy-loaded carousels, and three different chat widgets. On a product catalog page, that's 4–6 MB of stuff you don't need. Times 10,000 pages, that's the difference between a 20-minute run and a 3-hour run.
Here's the 10-line route handler I drop into every actor:
const BLOCKED = ['image', 'media', 'font', 'stylesheet'];
await context.route('**/*', (route) => {