Technical teams want to know the newest, most cutting-edge tools they can implement to give themselves a competitive advantage, whether it’s the latest developer framework or modern CI/CD practices that boost velocity. But there’s one tool from all the way back in the 1920s that can improve any organization, no matter its scale: the randomized, controlled trial—or simply put, experiments.
Even at a time when technologies and technical practices are changing faster than ever before, experiments never go out of style. Enterprise companies like Meta, Google, Amazon, and many more might run upward of 100,000 experiments every year because they provide the gold standard of scientific evidence: a way to use data and statistics to understand causation, not just correlation, between the changes we make and the metrics they affect.
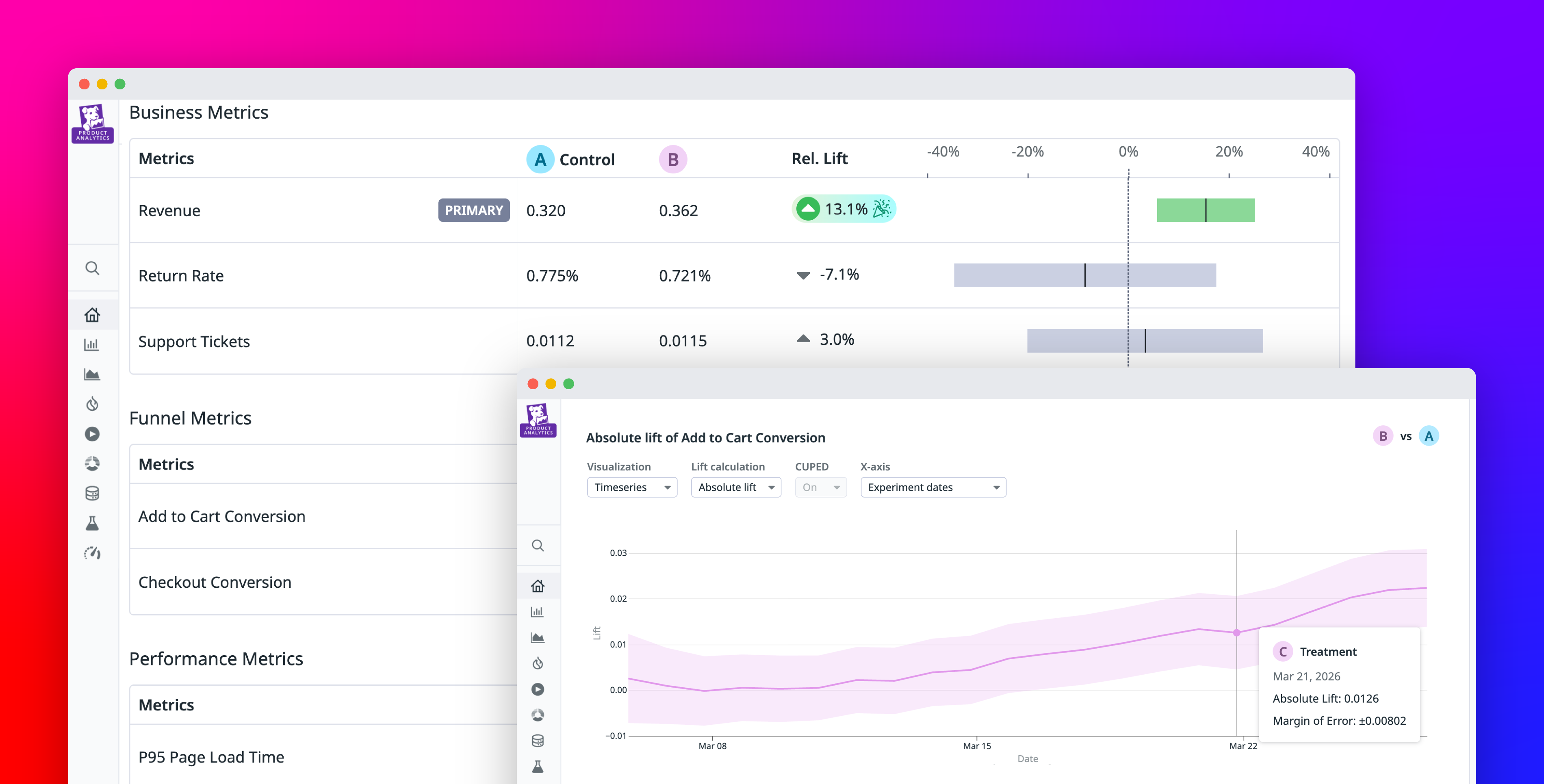
Experiments are often referred to colloquially as A/B tests, a term typically associated with growth and product teams looking to measure how users respond to changes in product features or UI designs. But experimentation helps us evaluate any decision we face, including whether new code is safe to deploy or how to configure AI models in production. By selectively enabling changes for a random sample, we can monitor potential impacts safely, quantify successes, and swiftly roll back failures. With this approach, you can run an experiment anywhere you have changes to make and metrics to measure.