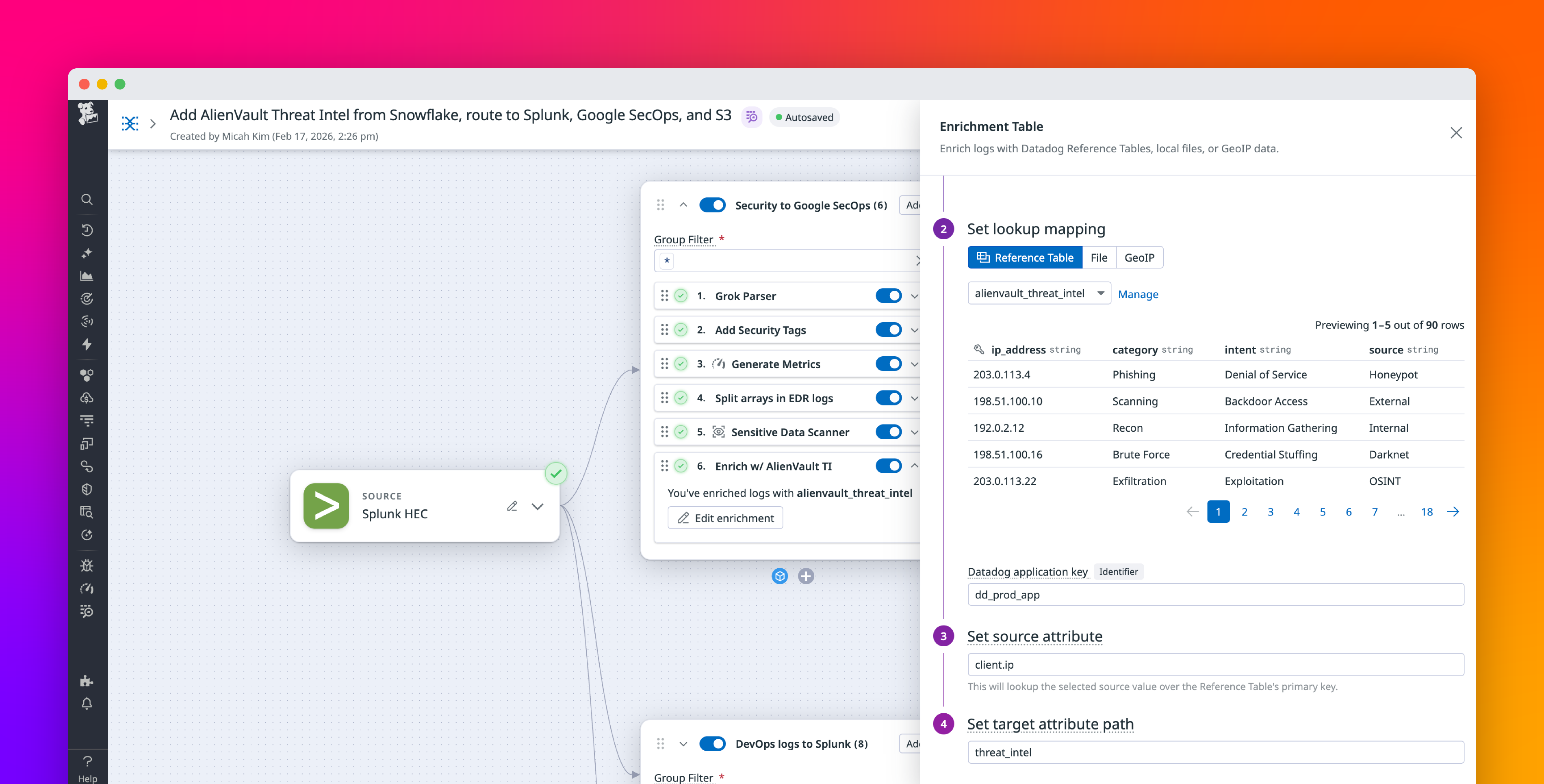
Security and platform engineering teams rely on context-rich logs to investigate threats, prioritize incidents, and meet compliance requirements. Context is often stored separately from applications that generate logs, in sources like threat intelligence feeds in Snowflake, asset lists in Amazon S3, ownership data in ServiceNow CMDB, and risk scores produced in Databricks. Enriching logs after ingestion means duplicating lookups in every downstream tool and manually correlating logs with external sources during every investigation. The results are slower resolution of performance and security issues as well as increased cost.
To address these challenges, Datadog Observability Pipelines supports centralized log enrichment with Reference Tables before you route data to your preferred SIEM, logging solution, or data lake. You can use dynamically updating Reference Tables that integrate with SaaS applications, data lakes, and cloud storage to attach fresh metadata to events before data leaves your infrastructure.
In this post, we’ll explain how Observability Pipelines helps you:
Centrally enrich logs with data stored in Reference TablesApply fresh context to data during threat investigationsProcess and conditionally route enriched data to your downstream logging tool, SIEM, or data lake