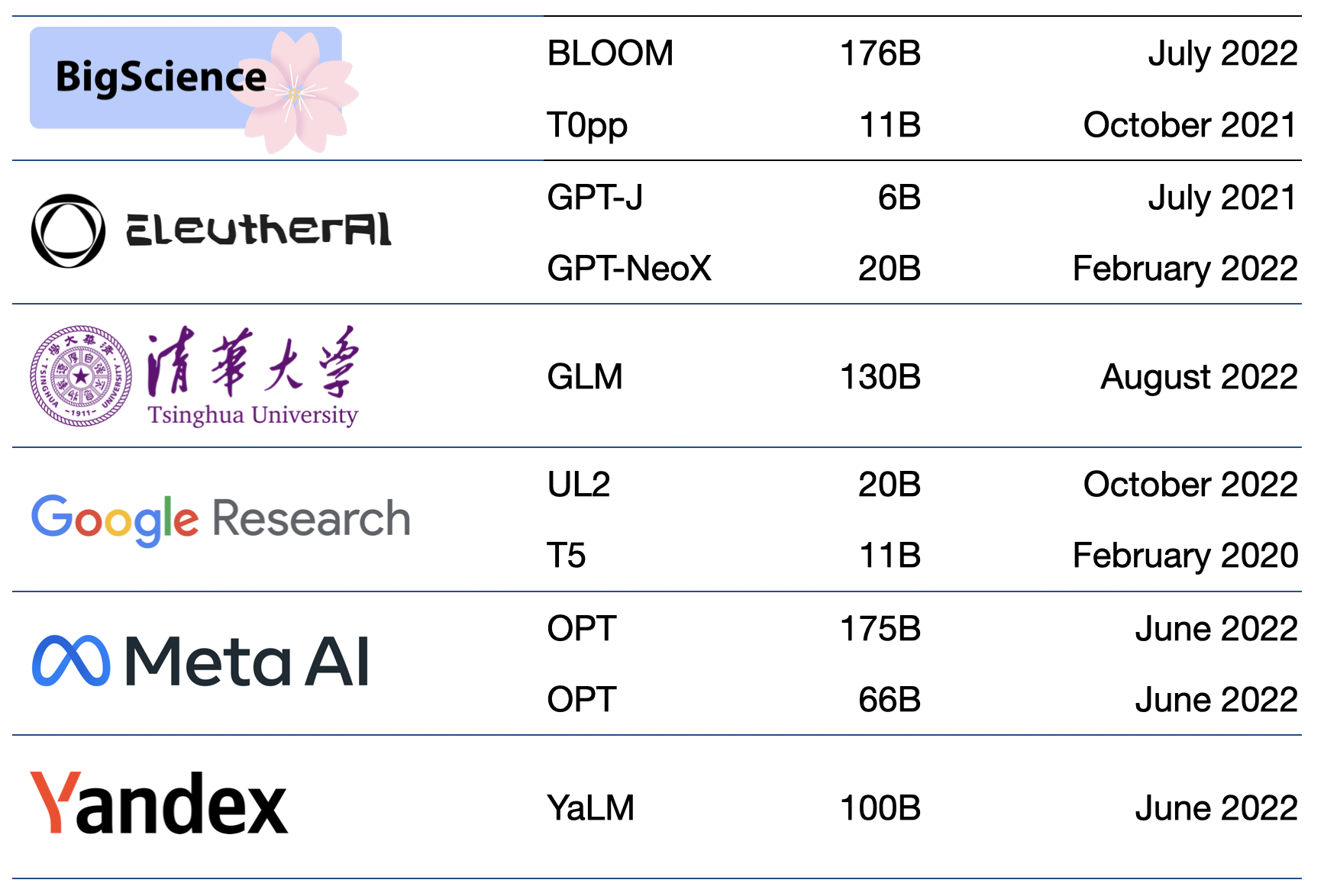
Cohere just released Command A+, as an open-source model targeting enterprise agentic workflows. Available under an Apache 2.0 license, Command A+ is a mixture-of-experts (MoE) model built for high-performance agentic tasks with minimal compute overhead. The model is optimized for reasoning, agentic workflows, RAG, multilingual, and multimodal document processing. It unifies capabilities from four prior models — Command A, Command A Reasoning, Command A Vision, and Command A Translate — into a single scalable model.
Architecture
Command A+ is a decoder-only Sparse Mixture-of-Experts Transformer with 218B total parameters and 25B active parameters. It has 128 experts, of which 8 are active per token, and a single shared expert is applied to all tokens. In a MoE model, each token is routed through only a subset of expert sub-networks rather than the full parameter set, keeping active compute at 25B-parameter scale at inference time.
The attention layers interleave sliding-window attention layers with Rotational Positional Embeddings and global attention layers without positional embeddings in a 3:1 ratio. The sparse MoE layer is trained in a fully dropless manner and uses a token-choice router, with a normalized sigmoid over the top-k expert logits per token.