My text-to-speech journey started roughly a year ago, when I tried it again and was impressed by how much faster it was than typing. I'd been fascinated by Churchill's use of a stenographer, and I knew it was a more efficient way to write things given proper editor post-processing. I'd tried dictation earlier, about 5 years ago, but it didn't work out - I tried using dictation and then sending it to people to transcribe, but it wasn't successful.
A year ago, I tried Whisper models with Python Qt, and it was fine. I used that initial Qt application for some time, but it was a bit ugly and not too easy to use. I found another application for Mac, and used it for a while.
After a year of using it almost every day, I've learned how to speak freely without hesitation. It's not perfect, but it's much faster, and I've been able to produce a lot more. A friend told me about Wispr Flow, which had a nice UI with a small overlay and simple key bindings. Although I didn't like the Electron application and the marketing, I picked the features I needed, like vocabulary, history of dictations, and key bindings.
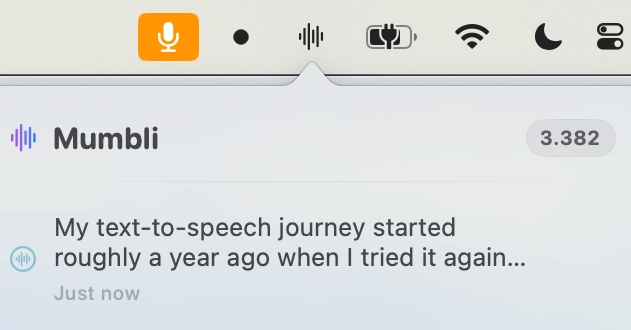
That's how I created Mumbli, and so far, it's working well - I'm over 3300 transcriptions now. I can tweak it and try new things, like new GPT live transcription models.