The problem isn't your prompts
If you're running Claude Code, Codex, opencode, or openclaw and the API bill keeps climbing, you've probably tried writing tighter prompts. That's not where the waste is.
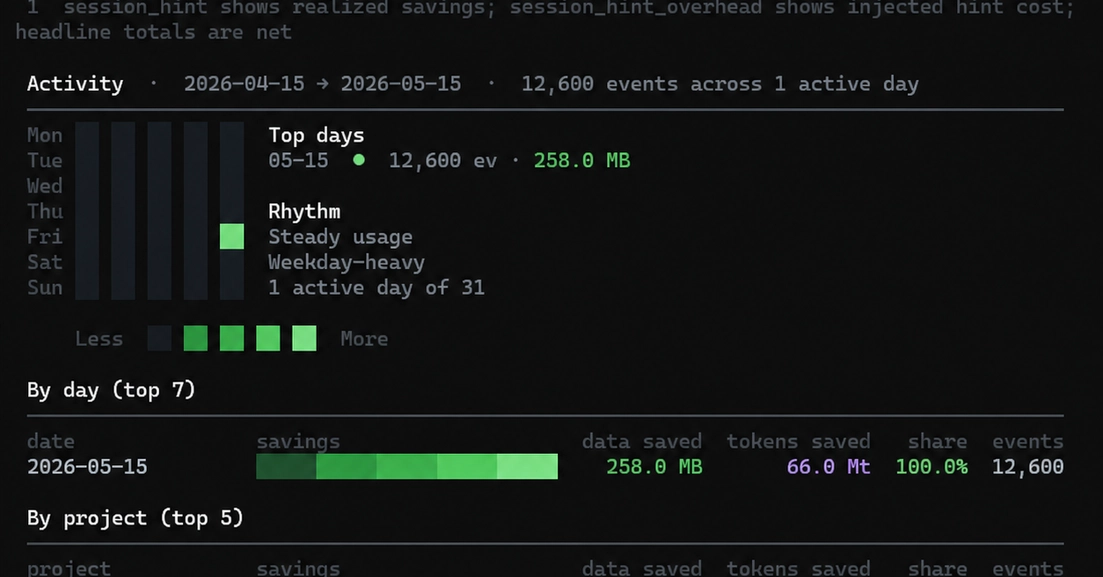
Four structural patterns account for most of the token spend in a typical session:
Screenshots at full resolution. The agent reads whatever images you paste or reference. A 3.3 MB screenshot from a high-DPI display lands in the model at full size. The model doesn't need native resolution to understand what's on screen.
Repeated file reads. The agent re-reads files it already touched earlier in the session. A 600-line file read three times costs 1,800 lines of tokens. There's no built-in session memory to prevent the second or third read from running the full price.





