This is a submission for the Gemma 4 Challenge: Write About Gemma 4
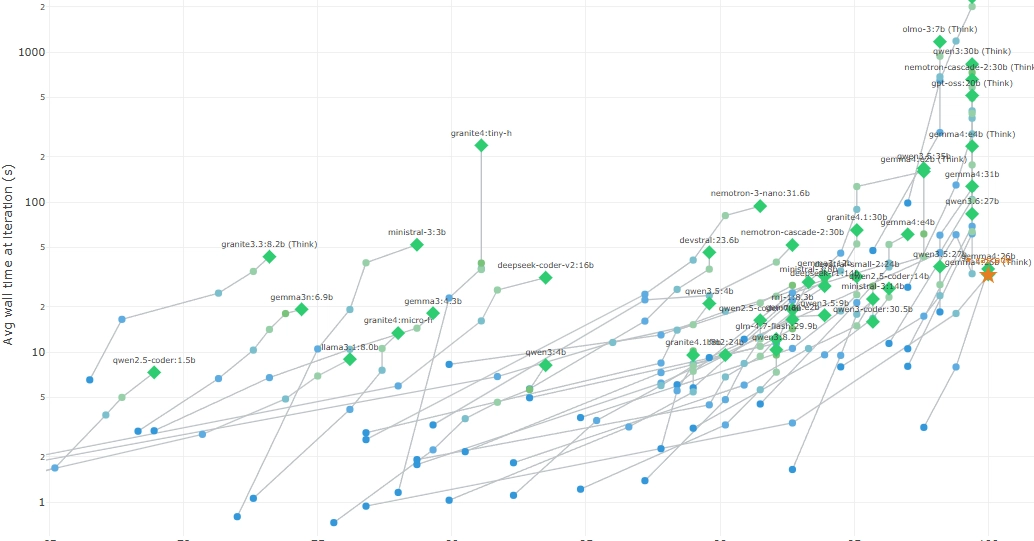
While running a simple harness around the HumanEval benchmark problems as test of local models, I was surprised to see gemma4:26b to be the first local model to pass the controversial HumanEval/145 question.
Not only had gemma4:26b solved it, it was also the only model to score 164/164, a perfect run.
I hadn't seen a single pass on HumanEval/145 in any of the ~50 runs with other models from the Gemma, Qwen, Deepseek, Mistral, Granite, LLaMA, OLMo, Nemotron,... families. Why?
HumanEval Leaderboard





